하이브리드 분석서버의 탄생
2011년 10월 IBM은 획기적인 대용량 데이터용 쿼리 가속기를 발표하였다. 여기에서 주목해야 할 정보는 두 가지가 있는데 첫째 2010년 9월에 인수한 네티자 (Neteza)를 바로 쿼리 가속기로 사용하였다는 점이고, 둘째 쿼리 가속서비스를 받는 플랫폼이 바로 우리가 익히 들어 알고 있는 메인프레임, 즉 System z 서버라는 점이다.
IBM은 이 대용량 데이터 쿼리 가속기를 IDAA (IBM DB2 Analytics Accelerator) 라고 명명하였는데 이는 메인프레임 기반의 DW 어플라이언스인 ISAS 9700 (IBM Smart Analytics System) 에 쿼리가속기 형태로 추가되는 옵션이다.
“똑똑한 분석 시스템 (ISAS)과 분석 극대화를 위한 분석가속기 (IDAA)”, 왜 IBM은 메인프레임 (대표적인 SMP, High End Server)과 네티자 (대표적인 x86 MPP, Extreme Analysis Server)를 한곳에 묶었을까? 그 이유는 바로 극단적으로 대조적인 성격을 가진 두 대의 서버를 하나의 인터페이스로 묶어서 올라운드 플레이어(All-round player), 시스템으로 얘기하자면 진정한 하이브리드 서버 (Genuine Hybrid Server)를 구현하고자 했기 때문인 것이다.
실제로 이 시스템은 메인프레임 DB2 옵티마이저의 판단아래, DB2가 직접 처리할 일과 IDAA에게 분석을 요청할 일을 구분하여 각각 해당 아키텍처에서 최적화된 워크로드를 처리하고 결과값만을 최종사용자에게 전달하는 방식으로 최종사용자는 메인프레임 DB2에게 요청할 뿐 DB2가 처리했는지 IDAA가 처리했는지, 아니 IDAA의 존재 자체를 알지 못한다고 표현하는 것이 맞다.

[그림 1] 에 보는 바와 같이 System z의 오랜전통인 가용성과 보안성, 뛰어난 동시 처리성 그리고 워크로드 관리자는 이미 업계에서 가장 뛰어난 서버로 인정받고 있는 항목이며, 특유의 FPGA를 활용한 고성능 대용량 데이터처리, x86 기반의 최적화된 병렬처리 프로세싱, 인덱스가 필요 없는 간편한 운영 등은 MPP 분야에서 이미 새로운 강자로 인정받은 지 오래이다. 두 시스템의 논리적인 통합으로 인해 고객은 올라운드 플레이어, 요즘 보고서에 자주 등장하는 OLTAP (OLTP 와 OLAP 의 합성어) 서버를 영입했다고 할만하다.
* FPGA(Field Programmable Gate Array)
FPGA 아키텍처는 프로그래밍이 가능한 대규모집적회로(LSI)를 이용한 지능형 디스크 컨트롤러로 디스크에 저장되어 있는 레코드나 칼럼 등의 데이터를 지능적으로 연속해 추출해 내는 기술로서 별도의 파티셔닝, 튜닝, 인덱스 생성 등이 없이 간편한 DB 운영을 가능하게 하면서 최고의 성능(경쟁사대비 10~100배 빠른 데이터처리)을 낼수있는 기술이다.
빅 데이터 vs 전통적인 EDW
앞서 다룬 전통적인 EDW 시장의 어플라이언스와 새로운 데이터 분석의 시장을 열어가는 빅 데이터는 강력한 경쟁 상대인가? 대답은 NO이다. 아래 질문과 답변을 보자. (빅 데이터 = Hadoop이라고 가정하자)
? 아직도 기업의 대부분 데이터는 정형화 되어있고 이들은 RDBMS를 통해 분석되고 있다 (맞다)
? 빅 데이터의 시대가 도래하면 데이터의 증가속도는 상상할 수 없을 정도일 것이며 금방 기존의 정형데이터 사이즈를 압도할 것이다 (맞다)
? 빅 데이터 시대가 도래하면 정형화된 RDBMS의 데이터를 모두 Hadoop으로 마이그레이션 하게 되고 결국 빅 데이터 플랫폼만 남을 것이다 (아니다)
? 빅 데이터는 임시적일 뿐 결국 모든 데이터는 전통적인 RDBMS로 수렴될 것이다 (아니다, 한 건 한 건 정합성을 보장하기 위해 많은 리소스를 써야 하는 RDBMS 에게 빅 데이터는 너무나도 큰 사이즈인 반면 비즈니스적인 의미는 상대적으로 적다)
위의 간단한 네 가지 질문만 보아도 빅 데이터와 전통적인 EDW 시장은 독립적으로 성장할 것이며 기업내의 중요한 데이터 분석 플랫폼으로 양립하게 될 것이라는 것을 잘 알 수 있다.
그러므로 오히려 두 플랫폼간의 정보의 상호보완성과 이를 활용하는 연결성(Connectivity)이 핵심이슈가 되는 것은 자명한 일이다.
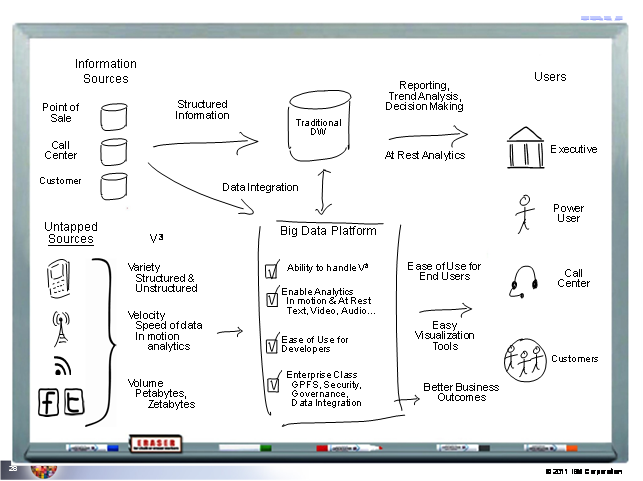
결론적으로 전통적인 DW 영역에는 하이브리드 분석서버 (ISAS 9700 & IDAA)를 적용하여 대용량 정형데이터의 고성능 분석 처리 및 급격히 증가하는 사용자를 수용하고 다양한 워크로드를 처리 및 관리할 수 있는 OLTAP 시스템을 구성하고, 빅 데이터 영역에 IBM의 Big Data 솔루션을 적용하여 V3 (Variety-정보의 다양성, Velocity-정보의 빠른 속도, Volume-정보의 빠른증가)를 지원하는 시스템을 구현하면서 전통적인 DW와 jaql을 통해 데이터를 주고 받는 상호 연계성을 확보하게 되면 빅 데이터의 시대에 가장 똑똑한 분석 시스템을 구현 할 수 있으리라 생각된다. 특히 또 메인프레임 기반의 하이브리드 분석서버는 추가적 의미로 사용자 측면의 +V3 (Variety-사용자의 다양성, Velocity-빠르게 변하는 사용자의 요구, Volume-사용자의 빠른 증가) 에 대응 가능한 적절한 솔루션이다.
* jaql
IBM이 개발한 Query Language로서 SQL과 흡사한 형태로 구성되어 IBM 의 Big Data 솔루션과 DB2, Netezza, JDBC DBMS 등의 저장공간에 read/write가 가능한 유연성이 높은 Query Language이다.
빅 데이터 전통적인 EDW 의 공존방식
앞서 언급한 바와 같이 전통적인 EDW 와 빅 데이터 영역은 독립적으로 공존하게 될 것인데 [그림 3] 과 같은 방식으로 비정형 대량 정보의 분석, 마이닝 후 비즈니스 적으로 의미 있는 데이터를 추출하고 정형 데이터로 영구저장하여 기존 분석데이터와 함께 분석이 용이한 환경으로 구현이 가능할 것이다.
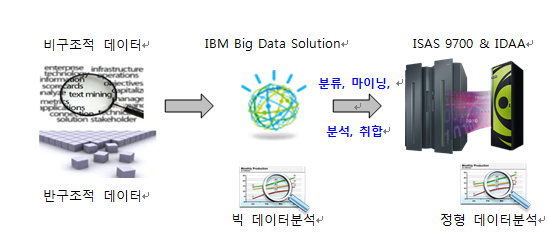
또한 반대의 경우로서 공존 모델 역시 구현이 가능할 것이다.
즉, [그림 4] 와 같이 기간계 / 정보계의 대용량 히스토리, 아카이브 데이터를 Big Data 솔루션 영역에 접목시켜 상시 분석할 수 있는 상태의 데이터로 활성화 시켜 빅 데이터 분석으로 활용이 가능하다.
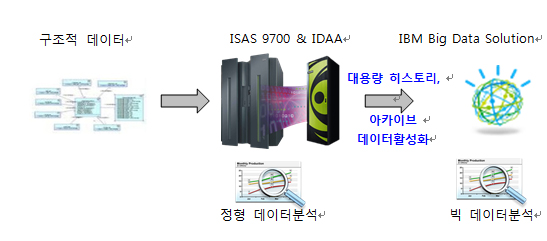
이와 같이 빅 데이터와 전통적인 EDW 시스템은 원천정보 측면에서 상호 보완적인 관계를 이루어 갈 것이며, 이로 인해 다양해진 시스템 활용도는 높은 가용성과 다양한 워크로드의 관리능력을 요구하게 될 것이다. 그렇다면 전통적인 EDW 에서 빅 데이터 에 이르는 분석 플랫폼으로서 메인프레임 역할을 다시 한번 생각 해보도록 만드는 계기가 될 것이다.