메모리 반도체 업계가 HBM4 양산을 목전에 두고 차세대 기술 'HBM-PNM' 연구에 본격적으로 뛰어들고 있다. 그래픽카드(GPU) 중심 아키텍처의 한계를 넘어 메모리 자체에서 연산을 처리하는 '계산 가능 메모리' 중심 시대를 준비하는 움직임으로 주목된다.
11일 업계에 따르면 삼성전자, 엔비디아, UC 샌디에이고, 컬럼비아 대학, 연세대 공동 연구팀은 최근 아카이브(arXiv)에 AMMA(A Multi-Chiplet Memory-Centric Architecture) 기술에 관한 논문을 발표하며 HBM-PNM 기술의 실현 가능성을 제시했다.
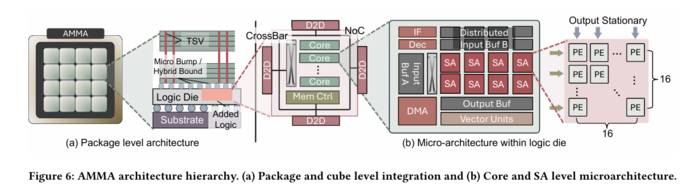
PNM(Processing Near Memory)은 HBM 스택의 로직 다이(Logic Die)에 특별한 계산 유닛을 배치해 메모리 바로 옆에서 '직접' 연산을 수행하는 기술이다. 기존 PIM(Processing In Memory)이 메모리 셀 안에 계산 회로를 넣는 방식이었다면, PNM은 메모리 용량을 유지하면서도 훨씬 복잡하고 강력한 연산이 가능하다는 장점이 있다.
현재 거대언어모델(LLM) 서비스의 최대 병목은 디코드 단계의 어텐션(Attention) 연산이다. 긴 문맥의 디코드 어텐션을 할 때 GPU는 계산 능력의 95% 이상을 늘리고 메모리 대역폭만 풀가동하는 상황이 된다.
루빈(Rubin) GPU의 경우에도 패키지 면적의 67%, 전력의 73%를 차지하는 계산 다이(Compute Die)가 긴 문맥 상황에서는 실제로는 4~5% 정도밖에 활용되지 않는 것으로 분석됐다. 이는 자원 낭비이자, 전력 소비와 발열 문제를 키우는 주요 원인이다.
HBM4부터 로직 다이가 5나노미터 이하 첨단 공정으로 제작되면서 PNM 구현의 기술적 장벽이 낮아졌다. 연구팀이 제안한 AMMA는 기존 GPU의 계산 다이를 제거하고 16개의 HBM-PNM 큐브를 4×4 메쉬로 연결하는 구조다. 이를 통해 패키지 내 메모리 대역폭을 기존 대비 약 2배인 44TB/s까지 끌어올렸다.
실제 연구에서 AMMA 아키텍처는 엔비디아 H100 대비 어텐션 지연 시간이 15.5배 감소했고, 에너지 소비는 6.9배 줄었다. 차세대 루빈 GPU(Rubin GPU) 대비도 1.8~2.5배 빠른 속도와 2.6~3.1배 높은 에너지 효율을 보였다. 특히 100만 토큰(1M Context) 수준의 초장문맥 추론·에이전트 워크로드에서 강력한 성능을 나타냈다.
연구팀은 “이번 연구를 통해 GPU를 넘어 메모리 중심 아키텍처가 새로운 클래스(class)로 자리 잡을 가능성을 보여주고, 향후 이종(heterogeneous) 플랫폼에서 메모리 중심 가속기가 핵심 역할을 하는 차세대 시스템 연구를 촉진하고 싶다”고 밝혔다.
이형두 기자 dudu@etnews.com