








2026년 3월, 연구팀이 AI 모델 파인튜닝 과정에서 발생하는 메모리 낭비를 절반 이하로 줄이는 기술을 공개했다. 이 기술은 8~32B 규모의 대형 AI 모델에서 학습 속도를 최대 2배 가까이 높이면서도 GPU 메모리 사용량을 조건에 따라 최대 7GB까지 줄였다. 핵심은 기존 방식이 필요 없이 만들어내던 '512MB 규모의 임시 메모리 버퍼'를 아예 만들지 않는 것이다. 알고리즘 자체는 바꾸지 않고 계산 순서와 방식만 재설계해 같은 결과를 훨씬 빠르게 얻어냈다. 단일 GPU로 AI를 학습시키던 연구자와 기업에게 실질적 돌파구가 될 전망이다.
보이지 않는 메모리 괴물, 매번 512MB씩 만들었다 버린다
DoRA라는 파인튜닝 기법은 AI 모델의 가중치를 '크기'와 '방향'으로 분리해 학습 성능을 높인다. 문제는 이 분리 과정에서 매번 '행별 노름(row-wise norm)'이라는 계산을 해야 하는데, 주요 AI 학습 프레임워크 6개가 모두 이 계산을 위해 거대한 임시 데이터를 메모리에 만든다는 점이다. 마치 10페이지 문서를 복사하기 위해 매번 1000페이지짜리 백지 노트를 새로 만드는 격이다.
구체적으로는 8192 차원 모델에서 랭크 384 설정일 때, 단일 계산 모듈 하나당 약 512MB의 임시 메모리가 발생한다. 대형 AI 모델은 이런 모듈을 수백 개 포함하므로, 학습 과정에서 이 임시 메모리가 수백 번 반복 생성된다. 연구팀은 "가장 직관적인 해결책인 '직접 곱셈' 방식도 여전히 전체 데이터를 메모리에 펼쳐놓아야 해서, GPU 종류에 따라 오히려 더 느려지는 경우도 있었다"고 설명했다. 그래디언트 체크포인팅을 사용하면 이 메모리가 매 학습 단계마다 두 번씩 할당되면서, 메모리 부족 오류의 직접적 원인이 됐다.
수학 공식 쪼개기, 512MB를 17MB로 압축
연구팀의 해법은 놀랍도록 단순했다. 하나의 복잡한 계산식을 세 개의 작은 항으로 쪼갠 것이다. 마치 (a+b)²을 한 번에 계산하는 대신 a²+2ab+b²로 나눠 계산하면 중간 결과를 재활용할 수 있는 것과 같은 원리다. 이렇게 분해하면 512MB짜리 거대 데이터 대신 17MB짜리 작은 데이터 세 조각만으로 같은 결과를 얻을 수 있다. 이론상 메모리 사용량이 15분의 1로 줄어든다.
실제 측정 결과 메모리 감소량은 3.2배였는데, 이는 전체 계산 중 일부가 랭크(모델 압축 정도)와 무관하게 고정된 크기의 버퍼를 쓰기 때문이다. 그래도 이 버퍼는 256MB 예산 안에서 작동하며, 이론적으로는 미리 계산해서 저장해둘 수도 있다. 핵심은 이 모든 계산이 32비트 부동소수점 정밀도로 이뤄져 정확도 손실이 거의 없다는 점이다. DoRA 논문이 제시한 "노름 계산은 그래디언트 흐름과 분리된 상수로 취급하라"는 원칙을 충실히 따랐다.
4개 계산 단계를 1개로 합쳐 고속도로 만들기
메모리 절감만으로는 충분하지 않았다. 연구팀은 DoRA의 최종 합성 단계도 최적화했다. 기존 방식은 "(g1)×밑바탕 + g×배율×로라"라는 계산을 4개의 순차 작업으로 나눠 처리했다. GPU는 각 작업마다 메모리에서 데이터를 읽어오고 결과를 다시 써야 하므로, 총 12번의 메모리 왕복이 발생했다. 연구팀은 이를 '융합 커널'이라는 기법으로 단 1번의 왕복으로 압축했다. 메모리 트래픽이 4분의 1로 줄어든 셈이다.
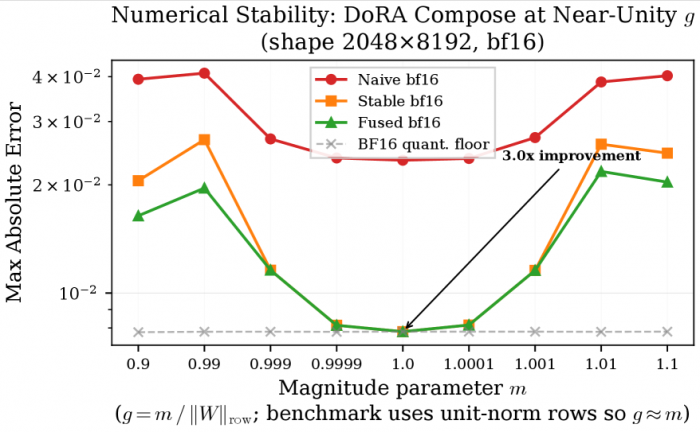
실제 속도 향상은 1.5~2.7배였다. 이론상 4배가 아닌 이유는 기존 방식이 작업 간 대기 시간 때문에 부분적으로 병목되어 있었기 때문이다. 융합 커널은 GPU 메모리 대역폭의 약 50%를 활용하는 반면, 기존 방식은 20%에 그쳤다. 더 중요한 건 수치 안정성이다. g 값이 1에 가까울 때(DoRA에서 매우 흔한 상황) 기존 계산 방식은 '파국적 소거'라는 현상으로 정밀도가 무너진다. 실제 측정 결과 Qwen2-VL-7B 모델에서 g 값의 100%가 이 위험 구역에 속했다. 연구팀의 안정화된 계산 방식은 오류를 약 3배 줄였다.
학습·추론·구형 PC, 상황별로 자동으로 최적 경로 선택
이 기술의 실용성은 '3단계 자동 전환' 시스템에서 빛난다. GPU로 학습할 때는 순전파와 역전파를 하나로 합친 '융합 역전파' 모드가 작동한다. 추론만 할 때는 역전파 계산을 아예 건너뛰는 '융합 순전파' 모드로 전환된다. CPU나 Triton 커널을 지원하지 않는 환경에서는 순수 PyTorch 코드로 돌아간다. 사용자가 별도 설정을 바꿀 필요가 없다.
전환 기준도 똑똑하다. 출력 차원이 2048 이상이고 (배치×시퀀스)×출력이 2048×6144 이상일 때만 융합 모드를 쓴다. 더 작은 계산에서는 커널 실행 준비 시간이 더 오래 걸려 오히려 손해이기 때문이다. 실제 테스트한 6개 대형 모델에서 레이어당 어댑터 모듈의 약 71%가 융합 모드를, 29%가 기본 모드를 사용했다. 모든 PyTorch 경로는 완전히 동일한 결과를 내지만, Triton 커널은 부동소수점 연산 순서 차이로 마지막 비트가 약간 다를 수 있다. 그래도 32비트 기준 오차는 0.0001 이내, 16비트는 해당 정밀도 한계 내에 머물렀다.
6종 GPU에서 모두 2배 빨라졌고, 학습 결과는 소수점 넷째 자리까지 일치
연구팀은 NVIDIA GPU 6종(L40S, A100, RTX 6000 PRO, H200, B200, B300)에서 대형 AI 모델 6개를 테스트했다. 결과는 일관됐다. 기존 Hugging Face PEFT 구현 대비 학습 속도가 1.46~1.87배, 자체 기본 구현 대비 1.18~1.24배 향상됐다. 추론 속도는 더 인상적이어서 PEFT 대비 1.5~2.0배, 기본 구현 대비 1.14~1.20배 빨라졌다. 순전파만 수행하는 추론에서 메모리 절감 효과가 더 직접적으로 드러나기 때문이다.
가장 저렴한 GPU인 L40S(메모리 대역폭 0.86TB/s)부터 최신 B200(7.7TB/s)까지 모든 GPU에서 일관된 개선이 나타났다는 점이 중요하다. 이는 특정 하드웨어의 특수 기능이 아니라 메모리 트래픽 감소라는 근본 원리에서 이득이 발생함을 의미한다. 정확도도 검증됐다. 최종 출력값 간 코사인 유사도가 모든 모델과 GPU 조합에서 0.9999를 넘었고, 고급 메모리를 쓰는 GPU에서는 0.999996 이상이었다. Qwen3.5-9B 모델로 2000단계 학습을 3번 반복한 결과, 평균 손실 차이가 0.00071에 불과했고 최종 평가 손실은 0.00009 차이였다.
FAQ(※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. AI 파인튜닝할 때 메모리가 부족한 이유가 뭔가요? AI 모델은 학습 중에 계산 결과를 임시로 저장했다가 바로 버리는 '휘발성 메모리'를 대량으로 씁니다. DoRA 같은 기법은 이 임시 메모리를 한 번 계산에 수백 MB씩 쓰는데, 대형 모델은 이런 계산을 수백 번 반복하면서 메모리가 부족해집니다.
Q. GPU마다 최적 설정이 다른 이유는 무엇인가요? GPU 칩 설계가 세대별로 다르기 때문입니다. 메모리 접근 속도, 계산 유닛 개수, 캐시 구조 등이 달라서 같은 코드라도 GPU마다 가장 빠른 실행 방식이 다릅니다. 연구팀은 각 GPU가 처음 실행될 때 10~30초간 자동으로 최적 설정을 찾게 했습니다.
Q. 이 기술은 개인 연구자에게 어떤 의미가 있나요? 단일 GPU 환경에서 다룰 수 있는 모델 규모와 학습 안정성이 눈에 띄게 개선됩니다. 기존에는 메모리 부담 때문에 고랭크(High-rank) DoRA 설정이나 대형 모델 실험이 어려웠지만, 이 기술을 적용하면 메모리 사용량이 줄어 더 높은 설정으로 실험할 수 있습니다. 또한 전체 학습 시간도 약 8% 정도 단축돼 전기료나 클라우드 비용 절감 효과를 기대할 수 있습니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: Scaling DoRA: High-Rank Adaptation via Factored Norms and Fused Kernels
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)


































