"AI가 일자리를 대체한다"는 말은 절반만 맞았다. 워싱턴대학교(University of Washington)를 중심으로 한 연구진이 발표한 잡벤치(JobBench)는 사람들이 정말로 AI에게 떠넘기고 싶어 하는 일이 무엇인지부터 물었고, 그 일을 가장 잘한다는 AI에 시켜봤더니 100점 만점에 45.9점밖에 받지 못했다. 잡벤치(JobBench)란 노동자가 직접 "이 업무는 AI에게 맡기고 싶다"고 답한 일만 골라 AI의 실력을 측정한 새로운 평가 기준을 말한다. AI가 내 일을 빼앗을지 걱정하기 전에, 정작 내가 떠넘기고 싶은 귀찮은 일을 AI가 해줄 수 있는지부터 따져봐야 한다는 발상의 전환이다.
일자리 대체에서 업무 보조로 바뀐 AI 평가의 기준
잡벤치(JobBench)의 핵심은 AI를 바라보는 질문 자체를 바꿨다는 데 있다. 그동안 나온 AI 업무 평가들은 거의 모두 "AI가 사람 일자리의 몇 퍼센트를 대신할 수 있나"라는 경제적 관점에서 출발했다. 대표적으로 GDPVal은 경제적 가치가 큰 업무를 골라 AI가 전문가 수준의 결과물을 내놓는지 평가했다. 연구진은 이런 방식이 결국 "AI가 사람을 대신한다(replacement)"는 이야기만 반복한다고 봤다.
잡벤치는 반대로 "보조(enhancement)"에서 출발한다. 워크뱅크(WorkBank)라는 설문에서 1,500명이 넘는 노동자가 자기 직업의 모든 업무를 하나하나 보며 "이건 AI에게 맡기고 싶다"고 답한 데이터를 기반으로 삼았다. 그중 노동자들이 가장 떠넘기고 싶어 한 업무, 동시에 경제적 비중도 큰 35개 직업을 골라 130개의 실전 과제로 만들었다. 사람을 밀어내는 일이 아니라, 사람을 거들어 만족도와 생산성을 함께 끌어올리는 일을 측정하겠다는 것이다.
35개 직업 130개 과제, 최강 AI도 45.9점에 그친 성적표
잡벤치는 35개 직업에 걸친 130개 과제로 구성된다. 절반인 65개는 까다로운 본 과제(Main set), 나머지 65개는 비교적 쉬운 과제(Easy set)다. 각 과제에는 CSV, PDF, 엑셀, 워드 등 17가지 형식의 참조 파일이 평균 3.9개씩 딸려 있어, AI는 흩어진 자료를 직접 읽고 짜맞춰야 한다. 채점 기준은 무려 4,631개의 합격·불합격 항목으로, 과제 하나당 평균 35.6개의 항목을 통과해야 한다.
연구진은 36가지 AI 설정을 시험했다. 가장 높은 점수를 받은 것은 클로드 코드(Claude Code) 위에서 돌린 클로드 오푸스 4.7(Claude Opus 4.7)로, 100점 만점에 45.9점이었다. 그다음은 코덱스(Codex)에서 돌린 GPT-5.5가 42.7점, GPT-5.4가 38.9점이었다. 그런데 클로드(Claude)와 GPT 계열을 벗어나면 점수가 급락했다. 그 외 어떤 모델도 19점을 넘지 못했고, 가장 낮은 그록 4.2 패스트(Grok-4.2-Fast)는 4.38점에 머물렀다. 절반도 못 넘긴 1등과 한 자릿수에 그친 꼴찌의 격차는, 사람들이 진짜 원하는 일 앞에서 AI들의 실력 차이가 얼마나 벌어지는지 보여준다.
흩어진 자료를 짜맞추고 연쇄 채점을 통과해야 하는 난이도
잡벤치가 어려운 이유는 AI에게 깔끔하게 정리된 문제를 주지 않기 때문이다. 실제 직장 일이 그렇듯, 서로 어긋나는 자료가 섞인 어수선한 작업 공간을 던져준다. 예를 들어 기자 직군 과제에서는 수질 데이터 CSV, 미국 환경보호청(EPA) 지침, 연도별 감시 데이터를 교차 대조해 기준치 초과 여부를 확인하고, 위험 지역을 가려낸 뒤 편집용 자료 묶음을 완성해야 한다. 이는 워크뱅크 설문에서 기자들이 가장 맡기고 싶어 한 업무, 즉 "여러 출처를 대조해 사실을 확인하는 일"을 그대로 옮긴 것이다.
채점 방식도 가혹하다. 잡벤치는 채점 항목들을 사슬처럼 엮은 연쇄 평가(chained rubric)를 쓴다. 연쇄 평가란 하나의 추론 과정에 걸린 모든 항목이 동시에 통과해야만 점수를 주는 방식을 말한다. 맞는 사실을 우연히 맞혔더라도 그 사실에 이르는 추론 단계가 틀렸다면 부분 점수는 없다. 그럴듯한 답을 내놓고도 방법론 검증이나 기준치 확인 단계를 슬쩍 빠뜨리면 그 사슬 전체가 통째로 0점이 된다. 사람 전문가라면 결론을 방어하기 위해 당연히 밟았을 단계를, AI도 빠짐없이 밟았는지를 본다는 뜻이다.
포화 상태의 기존 시험 vs 40점에 막힌 잡벤치
잡벤치가 던지는 가장 날카로운 대비는 기존 평가와의 점수 차이에 있다. GDPVal에서는 AI들이 이미 천장에 닿았다. 코덱스에서 돌린 GPT-5.4는 GDPVal에서 83.0점, GPT-5.3 코덱스는 70.9점을 받았다. 그런데 같은 AI들이 잡벤치 본 과제에서는 각각 38.9점과 33.7점으로 반 토막 났다. 시험지만 바꿨을 뿐인데 점수가 절반으로 떨어진 것이다.
차이는 일의 성격에 있다. GDPVal이 측정한 것은 이미 정리된 자료 묶음을 받아 깔끔한 결과물을 만들어내는 일이다. 반면 잡벤치가 측정한 것은 사람들이 정작 귀찮아서 떠넘기고 싶어 한 일, 즉 어수선한 자료를 뒤져 사실을 대조하고 근거를 맞춰가는 사전 작업이다. 같은 GPT-5.4 코덱스가 잡벤치 본 과제를 푸는 데는 GDPVal의 2.4배에 달하는 시간이 걸렸다. AI가 잘 보이려고 만든 결과물과, 사람이 실제로 떠넘기고 싶은 수고로움은 전혀 다른 차원의 문제라는 신호다.
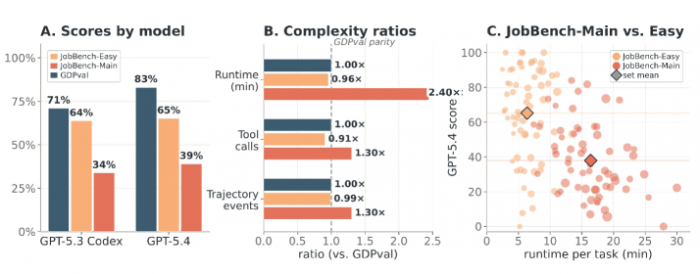
그림1. GDPVal 대비 절반 이하로 추락한 잡벤치 점수와 최대 2.4배 늘어난 작업 부담 (출처: JobBench 논문 Figure 4)
정작 AI가 약한 곳을 비껴가는 연구와 창업의 관심
연구진은 한 걸음 더 나아가, 학계와 스타트업이 어느 직업에 관심을 쏟는지도 분석했다. 2025년 4월부터 2026년 3월까지 나온 AI 에이전트 관련 논문 2,932편과, 2006년 이후 와이콤비네이터(Y Combinator)에 합류한 AI 스타트업 2,089곳을 직업별로 분류한 것이다. 그 결과 관심이 몰리는 방향과 AI의 실제 실력은 어긋나 있었다. 관심과 AI 성능 사이의 상관관계는 논문이 -0.15, 스타트업이 -0.34로 모두 음수였다. AI가 이미 잘하는 영역(스위트 존, Sweet Zone)보다, 아직 잘 못하는 영역(R&D 사분면)에 관심이 1.5배 넘게 쏠렸다는 뜻이다.
방향도 갈렸다. 연구는 컴퓨터·정보 연구원이나 사회과학 연구보조처럼 지식이 많이 드는 직군에 몰렸고, 스타트업은 고객 서비스 담당자나 재무 관리자처럼 돈이 되는 직군에 몰렸다. 나는 어느 쪽 일을 하고 있는지 떠올려 보면, 내 업무가 AI 투자와 연구의 집중 대상인지 아니면 비껴간 사각지대인지 가늠해 볼 수 있다. 정작 사람들이 가장 맡기고 싶어 하면서 AI는 아직 서툰 업무가, 관심의 한가운데가 아니라 변두리에 남아 있을 가능성이 있다.
대체의 공포보다 먼저 따져볼 질문
잡벤치가 던지는 메시지는 AI 일자리 논쟁의 순서를 바꾼다. 그동안 우리는 "AI가 내 일을 대신할 수 있는가"를 먼저 물었지만, 이 연구는 "내가 떠넘기고 싶은 일을 AI가 제대로 해주는가"를 먼저 묻는다. 최고 성능 AI조차 그 답이 아직 절반에 못 미친다는 것은, 대체의 공포가 적어도 지금 시점에서는 과장됐을 가능성을 시사한다.
다만 이 결과를 "AI는 아직 멀었다"는 안심으로만 읽기는 이르다. 점수가 낮다는 것은 곧 개선의 여지가 크다는 뜻이기도 하고, GDPVal이 불과 몇 세대 만에 천장에 닿았던 전례를 보면 잡벤치 점수도 빠르게 오를 가능성을 두고 볼 필요가 있다. 분명한 것은, 일자리를 둘러싼 불안을 막연한 공포가 아니라 "어떤 업무가 실제로 위임 가능한가"라는 구체적인 질문으로 바꿔놓았다는 점이다. 그 질문에 대한 답은 독자 각자가 자기 업무를 들여다보며 직접 채워가야 할 몫이다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. 잡벤치(JobBench)는 기존 AI 평가와 무엇이 다른가요?
기존 평가가 "경제적으로 가치 있는 일을 AI가 대신할 수 있는지"를 봤다면, 잡벤치는 "노동자가 직접 맡기고 싶다고 답한 일을 AI가 해낼 수 있는지"를 봅니다. 1,500명 이상이 참여한 설문을 바탕으로 사람이 정말 떠넘기고 싶어 하는 업무만 골라 측정한다는 점이 가장 큰 차이입니다.
Q. 가장 성능이 좋은 AI는 어떤 모델이었나요?
클로드 코드(Claude Code) 환경에서 작동한 클로드 오푸스 4.7(Claude Opus 4.7)이 100점 만점에 45.9점으로 1위였습니다. GPT-5.5가 42.7점으로 뒤를 이었고, 클로드와 GPT 계열을 제외한 다른 모델들은 19점을 넘지 못했습니다.
Q. 점수가 낮다는 건 AI가 아직 쓸모없다는 뜻인가요?
그렇지 않습니다. 점수가 낮은 이유는 잡벤치가 일부러 어수선하고 까다로운 실제 업무를 골랐기 때문입니다. 쉬운 과제에서는 점수가 26~31점 더 높았고, 비교적 정리된 업무라면 AI가 충분히 보조 역할을 할 수 있다는 의미로 읽을 수 있습니다.
기사에 인용된 리포트 원문은 JobBench 홈페이지에서 확인할 수 있다.
리포트명: JobBench: Aligning Agent Work With Human Will
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)