







cip-5.5-agent·cip-5.5-mm 독자 모델 스택 5개 에이전트 전원 70점대 이상
정보 소실 감안 시 98%+ 정답률, 인간(92%) 상회
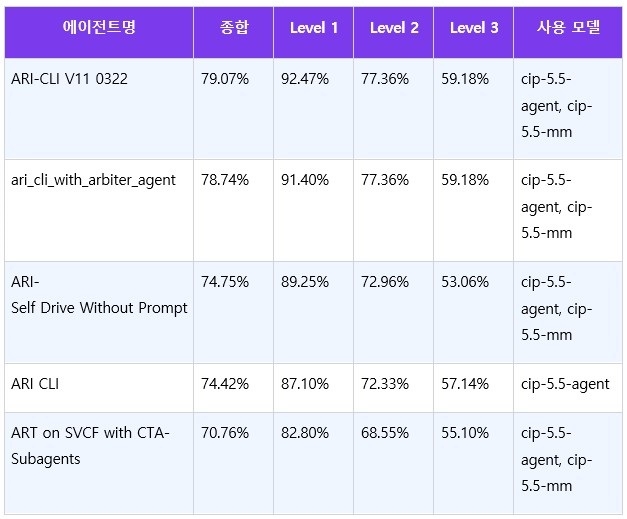
AI 스타트업 '클레비'가 from scratch 자체 모델을 활용해 글로벌 AI에이전트 벤치마크 'GAIA'에서 79.07%의 정답률을 기록했으며, 전체 3,090개 등록 모델 기준 상위 2.5% 이내에 안착했다.
업계의 설명에 따르면 AI 벤치마크 시장에서 GAIA는 '실용 AI 에이전트'의 능력을 충실히 반영한다는 평가를 받는다. 메타 AI와 HuggingFace, 파리-사클레 대학 등이 공동 개발한 이 벤치마크는 2023년 11월 처음 공개됐다.
GAIA가 다른 벤치마크와 구별되는 핵심은 세 가지다. 첫째, 정답이 비공개이기 때문에 과적합이 불가능하다. 둘째, 멀티스텝·멀티모달 복합 추론을 요구하기 때문에 단순 패턴 매칭으로는 고득점이 불가능하다. 셋째, 허깅페이스 공식 리더보드를 통해 전 세계 3,090개 이상의 모델이 동일한 조건에서 경쟁한다.
테스트셋은 총 301개 문항으로 구성된다. Level 1은 단일 도구 사용 및 단순 추론, Level 2는 다중 도구 조합과 중간 수준 추론, Level 3은 5단계 이상의 에이전트 계획과 실행이 요구되는 최고 난도 문항이다. 벤치마크 발표 당시 GPT 모델(플러그인 탑재) 기준 약 15%에 그쳤으며, 현재 상위권 팀들이 70~80%대로 끌어올린 상태다.
이 가운데, 클레비는 해당 성과에서 기술적으로 가장 주목해야 할 부분은 GPT, Claude, Gemini 등 외부 LLM API를 전혀 사용하지 않았다는 점이라고 강조했다. 클레비는 from scratch 방식으로 독자 개발한 두 가지 모델을 사용한 것이 특징이다.
cip-5.5-agent는 에이전틱 AI 모델로, 복잡한 작업을 자율적으로 계획(planning)·실행(execution)·검증(verification)하는 에이전트 파이프라인의 핵심 두뇌 역할을 한다. cip-5.5-mm은 음성·이미지·비디오 등 다양한 파일 포맷을 이해하고 추론하는 고성능 범용 멀티모달 모델이다. GAIA 문항의 상당수가 PDF, 이미지, 오디오 파일 등 비텍스트 입력을 포함하기 때문에, 이 멀티모달 능력이 고득점의 핵심 요인이 됐다.
클레비는 이 두 자체 모델을 기반으로 5개의 서로 다른 에이전트 구성을 GAIA에 출전시켰으며, 전원이 70점대 이상을 기록했다.
업체 측 설명에 따르면 클레비 내부 사후 검토에서 흥미로운 결과가 확인됐다. 총 301개 문항 중 일부는 현재 공개 웹상에서 정답 근거가 소실된 상태였다. 과거에는 온라인이나 검색 엔진에서 확인 가능했던 정보가 삭제·변경되어 더 이상 접근할 수 없는 경우다. 현재 사람이 공개적으로 확인 가능한 정보 범위 내에서 재평가했을 때, 클레비의 정답률은 98% 이상으로 나타났다. 이는 인간 평균인 92%를 이미 상회하는 수치다.
클레비 관계자는 “클레비는 외부 모델 혼합 없이, from scratch 자체 모델과 자체 AI 에이전트 솔루션만으로 5개 에이전트 전원 70+를 기록하며 공개 벤치마크에서 상위 2.5%에 진입했다. 향후 자체 모델·에이전트 솔루션 개선을 통해 공식 점수도 추가 향상이 가능할 것으로 보인다. 이번 성과는 글로벌 공개 벤치마크에서 실측돼 '검증된 신뢰'를 보여준다는 점, 국내 AI 개발사의 from scratch 자체 모델 기반 성과라는 점, 외부 모델 혼합이 아닌 독자 모델 스택 결과라는 점, 그리고 일부 문항의 정보 소실을 감안하면 점수 이상의 해석 가치가 있다는 점에서 의미가 깊다”고 설명했다.
이원지 기자 news21g@etnews.com





























