한국에너지공대(켄텍·KENTECH·총장직무대행 박진호)는 이석주 교수 연구팀이 비전-언어 모델(VLM)의 3차원(3D) 공간적 추론을 가능하게 하는 경량 프롬프트 학습 기술을 개발했다고 1일 밝혔다.
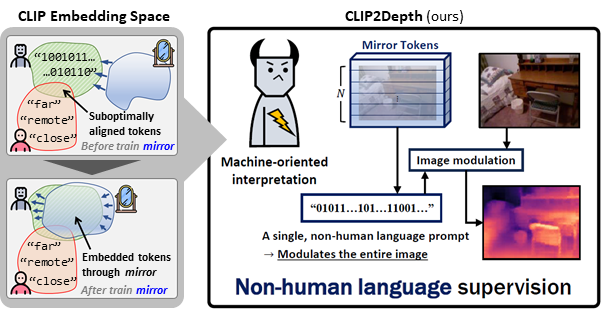
멀티모달 및 비전-언어 모델 대조적 사전학습(CLIP)은 이미지와 텍스트를 동시에 이해하는 인공지능으로, 비전과 자연어 처리 융합 분야에서 널리 활용한다. 예를 들어 '고양이'라는 단어를 보여주면 수많은 사진 속에서 고양이를 찾아내는 방식이다. 하지만 거리와 깊이 인식과 같은 기하학적 공간 이해 영역에는 한계가 있었다.
연구팀은 이를 극복하기 위해 사람이 쓰는 언어 대신, 기계가 이해하기 최적화된 새로운 표현 방식인 비인간 언어 프롬프트를 도입했다. 카메라에 찍힌 사진이나 영상만으로도 물체의 깊이를 정밀하게 파악할 수 있도록 했다.
실험 결과, 이번 기술은 약 110만 개 학습 파라미터만으로도 기존 3억개 이상의 대형 모델들과 견줄 만한 성능을 보였다. 필요한 파라미터 수가 300분의 1 수준으로 줄었지만, 성능 저하 없이 효과적인 학습이 가능했다.
연구진은 이 기술을 단일 카메라 기반의 깊이 추정 기법에 응용해 인공지능의 공간 이해 능력을 크게 향상시켰다.
이석주 교수는 “자율주행, 로봇 비전, 증강현실 등 경량화가 필수적인 다양한 공간 컴퓨팅 분야에 활용 가능한 핵심 원천기술로 자리매김할 것”이라고 말했다.
나주=김한식 기자 hskim@etnews.com