[솔루션 가이드] '페블러스 그린 데이터 플랫폼' 데이터 품질 평가와 최적화로 AI 적합성 부합하는 올인원 데이터 플랫폼
본격적인 인공지능 시대를 맞아 데이터 수요는 빅데이터에서 AI 레디(AI-Ready) 데이터로 방향이 전환되고 있다. 고품질 데이터의 수요는 급증하고 있지만, 기존 데이터 관리 체계로는 어떤 데이터가 중복되어 있는지, 데이터 세트가 편향적인지, 데이터 세트에 빈 부분은 없는지 알 방법이 없다. 이처럼 건강하지 못한 데이터는 인공지능 시스템의 성능 저하와 함께 계산 자원 및 에너지의 낭비도 초래한다.
또한 2024년 8월에 발표된 인공지능 규제법안 EU AI Act에는 적절한 데이터 거버넌스를 갖추지 못한 경우 전체 매출의 7% 또는 3500만 달러의 벌금을 부과하는 조항이 들어있어, 데이터의 품질을 보장하고 에너지를 낭비하지 않는 데이터 관리체계는 선택이 아닌 필수가 되었다.
각종 시장 조사 전문기관의 자료를 종합하면 고효율 친환경 AI 레디 데이터인 그린 데이터 시장은 AI 시장(150조원), 데이터 거래시장(287조원), 데이터 사이언스 시장(178조원)에 걸쳐 꾸준한 성장세를 보이고 있다.
이 중 SOM 영역은 1.17조원 규모의 SaaS 기반의 AI 레디 데이터 관리(Data Management) 시장으로 보고 있으며 글로벌 목표 점유율은 30%, 3500억원을 목표로 한다. EU AI Act 발효를 계기로 AI 규제가 강화되면서 관련 시장의 성장은 더욱 가속화될 것으로 예상된다.
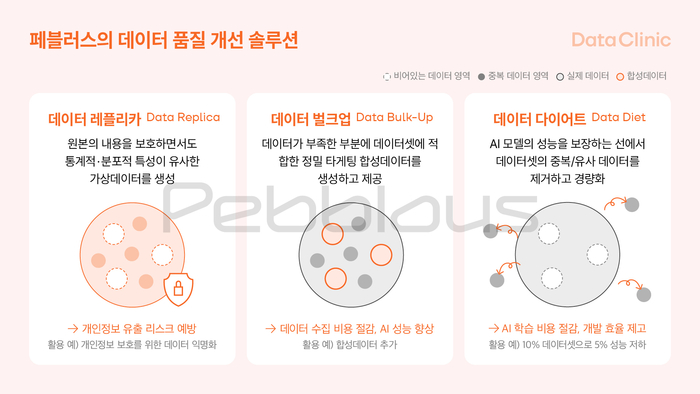
건강한 신체에 건강한 정신이 깃들 듯, 건강한 데이터가 건강한 인공지능을 만들 수 있다. 올인원 데이터 플랫폼 기업 페블러스는 데이터의 품질평가와 최적화를 통해 AI 적합성 기준을 만족하는 고효율 친환경 데이터인 그린 데이터(Green Data)를 지향한다.
그린 데이터를 위한 첫 단계는 데이터 진단 단계이다. 의미 기반 데이터 연산을 통해 이전에는 들여다 볼 엄두조차 낼 수 없었던 대용량의 복잡한 정형·비정형 데이터를 측정 및 관찰 가능한 형태로 변형하여 자동으로 품질 평가를 진행한다. 이를 기반으로 데이터의 중복이 심한 경우 데이터 경량화를 진행하고, 편향성이 있거나 부족한 데이터는 정밀 타게팅 합성 데이터의 생성을 통해 균질한 데이터로 변화시킨다.
또한 개인정보 보호를 위한 리플리카 데이터 생성과 의미 기반의 탐색·추론·결합을 통한 합성 데이터의 제공은 고객으로 하여금 보다 안전한 환경에서 더욱 다양한 분석을 할 수 있게 도와준다. 이를 통해 고객은 안전성, 효율성, 신뢰성을 확보한 AI 레디 데이터를 확보할 수 있다.
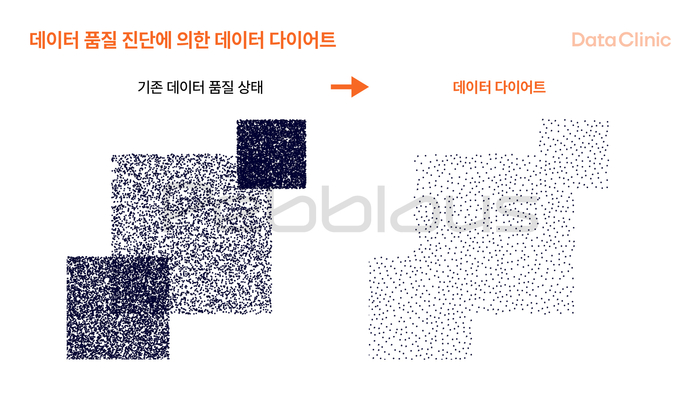
데이터의 중복은 AI 시스템의 효율과 에너지 효율에 악영향을 미친다. 또한 지나치게 편향된 데이터 분포는 편향된 결론을 유도하기도 한다. 페블러스의 데이터 다이어트는 정확한 진단에 의해 중복된 데이터의 영역을 자동으로 찾아내, 시스템의 성능을 최대한 유지할 수 있는 최적의 데이터 세트로 감량하여 준다.
페블러스의 고객사인 자이언트스텝의 경우 1.9M 이미지 데이터 세트에 대해서 데이터 경량화를 시행한 결과 단 10%의 학습데이터만으로 성능 저하 없이 인공지능 모델을 학습할 수 있었으며, 이를 통해 시간과 비용 등 인공지능 개발 효율을 대폭 향상시킬 수 있었다.

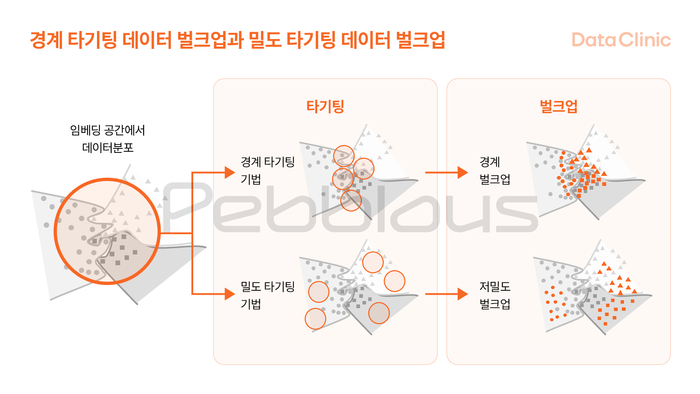
부족한 데이터를 인공지능 기술로 생성해주는 데이터 벌크업은 크게 두 방향으로 이루어진다. 대용량 데이터의 정밀 진단을 통해 데이터 벌크업이 필요한 공간을 찾아낸 후 특정 부분의 데이터의 밀도가 부족해 시스템의 편향성이 우려되는 경우 밀도 타게팅 데이터 벌크업이 이루어진다. 데이터 클라스 간의 경계 부분에 데이터가 부족하면 분류 오류가 발생하기 쉽다. 이 경우에는 경계 타게팅 데이터 벌크업이 필요하다.
인공지능 데이터 저장소인 캐글에서 7만여 장, 450개 클래스로 이루어진 Bird-450 데이터 세트를 대상으로 실험한 결과 5%의 합성데이터를 추가해 2%의 시스템 성능 향상을 얻을 수 있었다. 모든 벌크업은 생성형 인공지능 기술을 기반으로 기존 데이터 세트의 특성을 유지하도록 자동 생성되는 것도 페블러스만의 특장점이다.
데이터 기반 인공지능 시스템의 문제점 중 하나가 방대한 데이터의 우주를 들여다볼 수 없다는 점이다. 데이터를 기반으로 여러 문제를 풀고 해법을 제시하지만 정작 사용자도, 엔지니어도 데이터 전체를 조망할 수 없다. 이러한 문제점은 페블러스의 3D 대화형 데이터 탐지 시스템인 페블로스코우프(PebbloScope)가 해결한다.
대부분의 데이터는 방대한 양 뿐 아니라 복잡한 고차원 형태를 가지고 있어 사용자가 직관적으로 관찰할 수 없다. 페블러스의 데이터렌즈(DataLens)를 통해 관찰 가능한 차원으로 변환된 데이터는 페블로스코우프(PebbloScpoe)를 통해 3차원 공간에서 자유롭게 관찰할 수 있다. 이 과정을 통해 사용자는 데이터의 특징을 직관적으로 불 수 있을 뿐 아니라, 데이터 세트에 숨겨져 있는 숨겨진 특징도 발견할 수 있다.
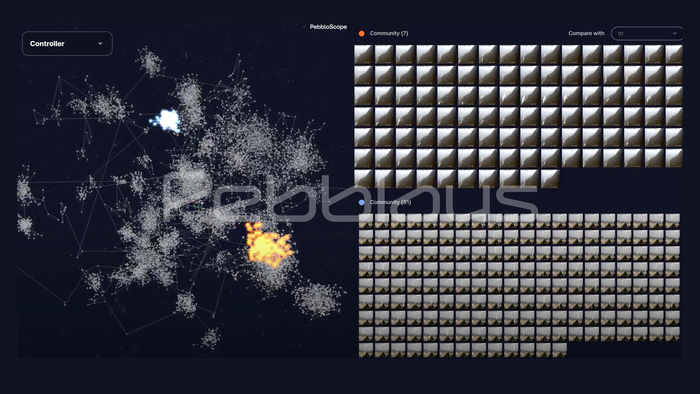
데이터는 살아 움직이는 생명체와 같다. 새로운 환경에서 새로운 데이터가 지속적으로 만들어지고, 사용 연한이 지난 낡은 데이터는 소멸시켜야 한다. 이처럼 다이나믹하게 변화하는 데이터의 AI 적합성을 지속적으로 평가하고 개선하기 위해서는 지금과는 다른 데이터 거버넌스가 필요하다.
페블러스는 의미기반으로 대용량 데이터의 품질을 평가하고 데이터의 수명주기를 유연하게 관리하며 지속 가능한 AI를 위해 데이터의 안전성과 윤리성을 검증하는 SaaS 기반 차세대 데이터 매니지먼트 솔루션 데이터 그린하우스를 출시할 계획이다. 이를 기반으로 인공지능 시대, 가장 중요한 AI 레디 데이터, 그린 데이터 시장을 선도하는 글로벌 기업으로 성장할 것으로 예상된다.
[알림] 전자신문인터넷과GTT KOREA가 오는 9월 27일(금) 서울 양재동 엘타워 그레이스홀(양재역)에서 공동으로 주최하는 “NABS(Next AI & Bigdata Summit) 2024”에서는 “비즈니스에 성공하는 AI & Big Data 혁신 전략”을 주제로 글로벌 AI와 빅데이터 산업을 이끌고 있는 글로벌 리더 기업들이 급변하는 기술과 비즈니스 환경에서 생산성과 효율성 및 비용 절감까지 조직과 비즈니스를 혁신할 수 있는 맞춤형 차세대 AI와 빅데이터 전략을 제시합니다.
유은정 기자 judy6956@etnews.com