







푸리에 분석으로 들여다본 거의 모든 AI 언어 모델은 숫자를 표현할 때 똑같은 주기 패턴을 만들어냈다. 그런데 그 표현으로 실제 수학을 풀 수 있는지 측정해보자, 일부 모델은 진짜 모듈러 산술(특정 숫자로 나눈 나머지를 계산하는 방식)을 익혔고 일부는 단지 표면적인 신호만 모방하고 있었다. 서던캘리포니아대(USC)와 UC샌디에이고 공동 연구진이 2026년 4월 발표한 'AI 모델 숫자 표현의 수렴 진화' 연구는 모델이 진짜로 학습한 것과 학습한 것처럼 보이는 것을 구분하는 새로운 잣대를 제시한다. 챗GPT, 라마(Llama), 클로드 같은 거대 언어 모델 시대에 'AI가 무엇을 알고 있는가'를 판단하는 기준 자체가 흔들리는 발견이다.
11개 사전훈련 모델 모두에서 발견된 동일한 푸리에 패턴
USC와 UC샌디에이고 연구진은 GPT-2부터 라마-4(Llama-4) 스카웃 109B, 딥시크(DeepSeek)-V3 671B, 맘바(Mamba)-2.8B, 엑스엘에스티엠(xLSTM)-7B, 그리고 글로브(GloVe)와 패스트텍스트(FastText) 같은 고전적 단어 임베딩까지 11개 모델의 숫자 임베딩을 분석했다. 결과는 놀라울 만큼 일관됐다. 모든 모델이 주기 2, 5, 10에서 뚜렷한 푸리에 스파이크를 보였다. 푸리에 스파이크란 숫자 임베딩 안에 일정 주기로 반복되는 신호 패턴이 음악의 박자처럼 두드러지게 나타나는 현상을 말한다. 주기 10은 십진법 자릿수, 주기 2는 짝수와 홀수, 주기 5는 5씩 끊어 세는 구조에 대응한다.
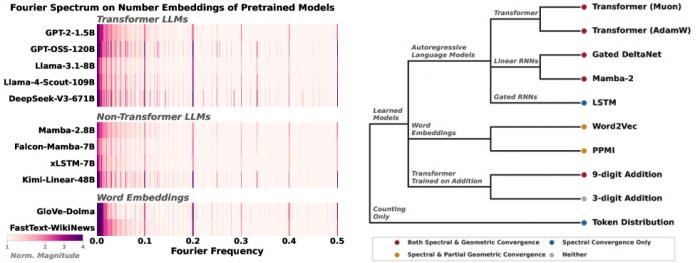
그림1. 11개 모델의 동일 푸리에 스파이크와 갈라지는 기하학적 수렴
연구진은 이를 '수렴 진화(Convergent Evolution)'에 비유했다. 척추동물의 눈과 문어 같은 두족류의 눈은 완전히 다른 진화 경로를 거쳤지만 결과적으로 매우 비슷한 구조에 도달했다. AI 모델도 마찬가지다. 트랜스포머(Transformer), 선형 RNN, LSTM, 단어 임베딩처럼 학습 알고리즘이 전혀 다른 시스템들이 숫자를 표현할 때 같은 주기 구조에 도달했다. 심지어 모델 없이 단순히 학습 데이터에서 숫자 토큰의 등장 빈도만 세어봐도 동일한 주기 스파이크가 나타났다. 학습 데이터 안의 숫자 분포 자체가 이미 강한 주기성을 띠고 있기 때문이다.
더 큰 스파이크 보였지만 수학은 못 푸는 LSTM의 역설
푸리에 스파이크가 보인다고 해서 모델이 숫자를 진짜로 이해한 것은 아니라는 점이 이 연구의 결정적 발견이다. 연구진이 동일한 100억 토큰 데이터로 3억 파라미터 트랜스포머와 LSTM을 따로 훈련시킨 뒤 모듈러 산술 능력을 측정하자 정반대 결과가 나왔다. 모듈러 산술이란 시계 바늘이 12를 지나면 1로 돌아가듯 일정 숫자로 나눈 나머지로만 값을 다루는 계산 방식이다. 측정 도구는 모델 임베딩에서 'n을 10으로 나눈 나머지'를 분류해내는 선형 분류기였다.
트랜스포머는 주기 10에 대해 코헨 카파(Cohen's κ) 85.4점을, LSTM은 2.0점을 기록했다. 코헨 카파는 무작위 추측을 0점, 완벽한 분류를 100점으로 잡는 지표다. 같은 데이터로 훈련받은 두 모델이 한쪽은 거의 완벽하게 숫자의 일의 자릿수를 구분해내는 반면, 다른 쪽은 동전 던지기 수준에 머물렀다는 의미다. 흥미로운 점은 LSTM이 트랜스포머보다 푸리에 스파이크 자체는 오히려 더 컸다는 것이다. 연구진은 이 두 차원의 학습을 구분해 부르기 시작했다. 스펙트럼 수렴(spectral convergence)은 다양한 모델이 동일한 주기 패턴을 보이는 현상이고, 기하학적 수렴(geometric convergence)은 그 표현으로 모듈러 산술을 실제로 분류할 수 있는 상태를 말한다.
연구진이 정리1(Theorem 1)로 증명한 내용도 같은 맥락이다. 푸리에 스파이크의 존재는 모듈러 분류에 필요조건이지만 충분조건은 아니다. 신호의 크기보다 그 신호가 클래스 내부 잡음과 어떻게 정렬되는지가 결정적이다. LSTM은 주기 신호를 만들어내긴 했지만, 그 신호가 잡음 방향과 겹치면서 분류기 입장에서는 활용 불가능한 형태가 됐다.
진짜 학습을 만드는 세 가지 조건, 데이터와 아키텍처와 옵티마이저
기하학적 수렴이 일어나려면 데이터, 모델 구조, 최적화 방법(옵티마이저) 세 가지가 모두 맞아떨어져야 한다는 것이 연구의 핵심 결론이다. 연구진은 데이터 쪽에서 네 가지 변형 실험을 설계했다. 모든 숫자 토큰을 빈도 분포에서 독립적으로 다시 뽑은 '유니그램 대체(Unigram Replace)' 조건에서는 푸리에 스파이크는 거의 그대로였지만 모듈러 분류 성능은 무작위 수준으로 떨어졌다. 숫자끼리의 등장 순서(n-gram)는 유지하되 특정 숫자와 그 주변 텍스트의 결합 관계를 끊은 '숫자 교체(Swap Numbers)' 조건에서는 주기 10 분류 성능이 85.4점에서 28.8점으로 떨어졌다. 텍스트와 숫자가 함께 등장하는 공기 관계가 진짜 학습의 결정적 신호임을 보여준다.
아키텍처도 결정적이었다. 동일 조건에서 트랜스포머와, 게이티드 델타넷(Gated DeltaNet)·맘바-2 같은 선형 RNN은 모두 강한 기하학적 수렴을 보였지만 LSTM은 무엇을 해도 무작위 수준에 머물렀다. 4층짜리 LSTM과 12층짜리 LSTM 결과가 같았기 때문에 단순히 모델 용량 문제는 아니라는 것이 확인됐다. 옵티마이저의 영향은 아키텍처에 따라 달랐다. 트랜스포머에서는 뮤온(Muon) 옵티마이저가 애덤더블유(AdamW)보다 주기 10 분류에서 85.4점 대 72.1점으로 앞섰지만, 맘바-2에서는 거꾸로 애덤더블유가 80.1점 대 76.7점으로 뮤온을 살짝 앞질렀다.
토크나이저가 결정한 산술 학습의 운명
산술 과제만으로 모델을 처음부터 훈련시켰을 때는 토크나이저(텍스트를 모델이 처리하는 단위로 잘라주는 도구)가 결정적 변수가 된다. 연구진은 9자리 덧셈과 3자리 덧셈 두 조건을 비교했다. 9자리 덧셈에서는 모든 피연산자와 결과가 1000 단위 토큰 여러 개로 나뉘기 때문에 각 출력 토큰 위치가 독립적인 1000 모듈러 분류 문제가 된다. 이 조건에서는 뮤온과 애덤더블유 두 옵티마이저 모두 거의 완벽한 모듈러 분류 성능에 도달했고 학습된 푸리에 구조도 거의 동일했다.
반면 3자리 덧셈에서는 모든 피연산자와 결과가 하나의 토큰으로 처리된다. 이 경우 모델은 모듈러 구조를 활용할 수밖에 없는 강제적 압력을 받지 않는다. 그 결과 같은 옵티마이저로 같은 데이터를 학습시켜도 시드 값에 따라 표현이 천차만별이었고 모듈러 분류는 무작위 수준에 머물렀다. 토크나이저가 데이터를 어떻게 자르느냐에 따라 모델이 진짜 수학적 구조를 학습할지, 단순히 외울지가 갈리는 셈이다.
표면 패턴만 보고 학습 여부 판단하면 안 된다는 경고
이 연구는 AI 해석 연구(인터프리터빌리티) 전반에 무거운 경고를 던진다. 모델 내부에서 어떤 패턴이 보인다고 해서 그 모델이 해당 개념을 기능적으로 학습했다고 결론내려서는 안 된다는 것이다. 그동안 여러 연구가 푸리에 스파이크의 존재만으로 'AI가 숫자의 모듈러 구조를 학습했다'고 해석해왔지만, 이번 연구는 그 추론이 신뢰하기 어렵다는 점을 정량적으로 보여준다.
연구진은 이 스펙트럼과 기하의 분리 현상이 숫자에만 국한되지 않을 가능성이 있다고 본다. 요일이나 달처럼 다른 주기적 개념에서도 같은 분리가 나타날 수 있다. 거대 언어 모델이 점점 더 다양한 분야에 활용되는 흐름 속에서, 표면적 학습과 진짜 기능적 학습을 구분하는 잣대는 두고 볼 필요가 있는 새로운 평가 도구가 될 가능성이 있다. 동시에 사용자 입장에서는 어떤 모델이 정말로 무엇을 이해하고 있는지를 단순한 시각화 결과로 판단하는 것이 위험하다는 점을 기억해둘 만하다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 푸리에 스파이크가 정확히 무엇인가요?
A. 푸리에 스파이크는 숫자 임베딩(컴퓨터가 숫자를 이해하기 위해 변환한 벡터값) 안에 일정 주기로 반복되는 신호가 강하게 두드러지는 현상입니다. 음악에서 일정 박자가 두드러지듯, AI가 학습한 숫자 표현 안에 '10마다 반복', '2마다 반복' 같은 주기 구조가 들어 있는지를 푸리에 분석으로 확인할 수 있습니다.
Q2. 왜 LSTM은 더 큰 푸리에 스파이크를 보이는데도 수학을 못 풀까요?
A. 푸리에 스파이크는 신호의 존재만 보여줄 뿐, 그 신호가 다른 잡음과 어떻게 섞여 있는지는 알려주지 않기 때문입니다. LSTM의 경우 주기 신호가 강하긴 하지만 클래스 내부 잡음 방향과 겹쳐서 분류기가 활용할 수 없는 상태가 됩니다. 트랜스포머는 신호와 잡음이 분리되어 있어 모듈러 분류가 가능합니다.
Q3. 이 연구가 일반 사용자에게 어떤 의미가 있나요?
A. AI 모델이 어떤 개념을 '이해'한다고 평가할 때, 단순한 시각화나 표면 패턴만 보고 결론을 내리면 안 된다는 점을 시사합니다. 챗GPT나 라마 같은 모델이 숫자를 다루는 방식도 모델별로 차이가 있을 수 있으며, 모델 선택이나 활용 시 어떤 작업에 강한지 실제 성능을 검증하는 것이 중요합니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: Convergent Evolution: How Different Language Models Learn Similar Number Representations
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)





























