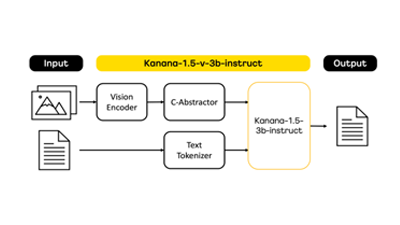
과학기술정보통신부가 한국지능정보사회진흥원(NIA)와 함께 '2024년 초거대 인공지능(AI) 확산 생태계 조성 사업'을 시작한다.
법률, 보건의료, 교육, 국방 등 총 10개 영역에서 63종 데이터를 AI 학습에 적합한 형태와 내용으로 확보·구축해 AI 허브에 공개한다. 추가로 7종의 데이터는 영역에 상관없이 수요가 있는 학습데이터를 구축한다. 데이터 과제(종)당 6억원을 지원하며 총 70종 학습데이터 구축에 420억원을 투입한다.
이번 사업은 초거대 AI 데이터를 구축·개방해 AI 생태계를 조성하고 AI 일상화를 실현할 수 있게 지원하는 게 목적이다.
대학, 공공기관, 정부, 지자체, 협회 등은 민간기업과 함께 컨소시엄을 구성해 참여, 초거대AI 학습에 필요한 데이터를 구축한다. 한국정보통신기술협회(TTA)가 데이터 품질을 검증한다.

법률분야에서는 사법·공법 분야 거대언어모델(LLM), 법률 문서 서식 데이터를 학습할 수 있는 데이터를 구축한다. 보건의료 분야는 피부질환·종양, 심리 상담 데이터, 교육 분야는 글쓰기·평가 데이터, 교과 데이터 등을 학습할 수 있는 데이터를 확보한다.
이외에도 국방에 군 경계 작전 데이터, 재난·안전·환경에 대기오염 배출원 공간 분포, 화학물질 위험성 등 다양한 산업에서 일상 데이터를 AI 모델에 학습할 수 있게 사업을 진행한다.
NIA는 대규모 데이터를 확보하고, 민간 데이터 구축 사업을 촉진해 체계적인 데이터 자원을 확보할 수 있게 돕는다. 이를 통해 AI 학습 데이터 부족 문제를 해소하고 국내 기업과 기관에서 AI 기술을 도입할 때 진입장벽을 낮출 방침이다.
민간 기업은 정부기관과 함께 학습 데이터를 구축하면서 AI 모델을 만드는 데 필요한 레퍼런스를 쌓을 수 있다. 구축된 데이터는 AI 허브를 통해 공개, 누구나 이용할 수 있게 한다.
박두호 기자 walnut_park@etnews.com