








최근 인공지능(AI)은 크게 발전했다. 산·학 연구개발자의 노력으로 알고리즘 수준은 향상됐고, 설계, 제조, 품질, 서비스, 마케팅 등 적용 사례도 증가하고 그 효과도 입증되고 있어, 이제 AI는 자타가 공인하는 기업의 미래 경쟁력을 좌우하는 핵심 요소가 됐다.
반면 일반 소비자는 아직 일상 생활에서 AI 기술을 크게 그리고 자주 체험하지는 못하고 있다. AI 만능 시대가 도래한 것처럼 관련 뉴스를 쏟아내는 각종 미디어의 보도와 달리, 소비자의 AI에 대한 체험과 체감의 정도는, AI 기술 발전 속도에 비해 기대 수준에 미치지 못하고 있는 것 또한 사실이다. 이처럼 AI에 대한 기대와 상용화 속도 간 차이를 보이는 원인은 무엇일까.
전문가들은 이구동성으로 AI를 학습시킬 데이터의 준비와 확보의 어려움을 그 원인으로 지목한다.
AI를 학습시키기 위해선 사람이 데이터에 일일이 정답을 표기하는 라벨링(Labeling) 작업을 해야 한다. 당연히 학습시킬 데이터가 많을수록, 라벨링 품질이 좋을수록 AI 성능은 향상된다. 그러나 이를 위해선 '인공지능 시대 인형 눈알 붙이기' 또는 'Click Farm'이라고 불릴 정도의 많은 노동력과 시간이 소요된다. 인공지능 시대의 그늘이자 장벽이자 일종의 '통곡의 벽'인 셈이다.
이 같은 '페인 포인트(Pain Point)'를 해결할 수는 없을까? 다시 말하면 '원시 데이터(raw data) 수집-데이터 분석 및 큐레이션(curation)-라벨링-검수-AI 학습/테스트/배포-성능 분석 및 진단'이라는 엔터프라이즈 레벨의 AI 개발 사이클(MLOps)에서, 사람의 수작업이나 엔지니어의 인사이트가 많이 소요되는 작업을 자동화하는 또 다른 AI 기술은 없는 것일까?
기자는 그 해답을 찾아보고자, 최근 AI 데이터 플랫폼 기업으로 주목 받고 있는 슈퍼브에이아이(Superb AI)의 김계현 CRO를 만나봤다. 슈퍼브에이아이는 창업 초기 세계적인 엑셀러레이터 와이콤비네이터의 투자를 받았을 뿐만 아니라, 최근 220억원 규모의 시리즈B 1차 펀딩 라운드를 마무리했다. 이번 펀딩에는 기존 투자자인 프리미어파트너스, 듀크대, KT 인베스트먼트 등과 신규 투자자인 산업은행, KT&G, 한라그룹 등이 참여했으며, 이로써 누적 투자금은 360억이 됐다.
▶ 최근 수년 동안 인공지능(AI)은 크게 발전했다. AI는 이제 사업을 혁신하고 미래 경쟁력을 좌우할 수 있는 핵심 요소가 됐다. 반면 일반 소비자는 아직 일상에서 AI 기술을 크게 체험하지 못하고 있다. 이처럼 AI에 대한 기대와 상용화 속도 간 차이를 보이는 이유는 무엇보다도 AI를 학습시킬 데이터의 준비와 확보의 어려움에 있다고 전문가들은 얘기한다. 슈퍼브에이아이는 이 같은 '페인 포인트'를 해결하고 있다고 들었다.
딥러닝으로 대표되는 기계학습 기법들이 도입되면서, 오늘날의 AI는 음성, 텍스트, 이미지와 같은 현실 세계의 비정형 데이터(unstructured data)로부터 유의미한 피쳐(feature)를 스스로 추출하고, 주어진 태스크(예: 이미지 분류, 문서 번역, 음성인식 등)를 수행하는 데 필요한 복잡한 지식을 스스로 모델링할 수 있게 되었다. 또한 수년간 네트워크 구조의 혁신을 거듭하며, 막대한 양의 데이터로부터 고도로 복잡하고 거대한 규모의 지식도 잘 학습해낼 수 있게 되었다.
즉 "충분한" 학습 데이터를 확보할 수 있다면, 일반 소비자가 일상에서 체험할 만큼의 고성능 AI(예: 테슬라의 자율주행 소프트웨어인 오토파일럿 이라든지, 구글의 다국어 통역 서비스 등)를 만들어낼 수 있는 기술적인 기반은 이미 어느 정도 마련되어 있다. 하지만 단순히 열심히 데이터를 모으고 라벨링하는 방식으로 '충분한' 데이터를 확보하려면 천문학적인 비용과 시간이 소요되는데, AI의 성능을 고도화하고자 할 수록 필요한 학습 데이터의 양은 기하급수적으로 증가하기 때문이다.
예를 들어, AI의 성능 향상을 위한 추가 학습 데이터로 'AI가 잘못 예측한 데이터' 100개를 수집한다고 하자. AI의 정확도가 90%라면, 1천 개의 데이터를 수집 및 라벨링(labeling)하고, 그 중 10%의 오류를 골라내어 100개를 수집할 수 있다. 정확도가 99%라면, 100 개를 얻기 위해 1만 개의 데이터에서 1%를 골라내야 하고, 99.9%라면 10만 개의 데이터에서 0.1%를 골라내야 한다.
슈퍼브에이아이는 시제품 수준의 초기 단계 AI에서부터 성능이 100%에 가깝게 고도화되는 단계까지 모든 과정을 효율적으로 수행할 수 있도록 하는 플랫폼을 만들고, 이를 통해 AI 전문가가 없거나 부족한 기업/조직/개인들도 AI를 개발하고 고도화할 수 있도록 하는 것을 목표로 한다.
이를 위해 구체적으로, [원시 데이터(raw data) 수집 - 데이터 분석 및 큐레이션(curation) - 라벨링 - 검수 - AI 학습/테스트/배포 - 성능 분석 및 진단] 이라는 엔터프라이즈 레벨의 AI 개발 사이클(줄여서 MLOps라고 부른다)에서, 사람의 수작업이나 엔지니어의 인사이트가 많이 소요되는 작업들(데이터 분석 및 큐레이션, 라벨링, 검수, 성능 분석 및 진단)을 자동화하는 AI 기술, 다시 말하면 'AI 개발을 위한 AI 기술'을 개발하고 있다.
라벨링 자동화, 검수 자동화, 데이터 분석 및 큐레이션 자동화 기술은 제품화하여 서비스 중에 있으며, 국내 완성차 및 차량 부품사의 자율주행 AI 학습 데이터 구축 비용을 1/3로 절감(66% 절감)하는 등, 국내외 다양한 고객사들의 AI 개발 비용을 절감하는 데 도움을 주고 있다. 성능 분석 및 진단 자동화 기술은 내년 초 출시를 목표로 개발 중이며, 기 출시된 기술들 또한 계속해서 기능 확장 및 고도화 하고 있다.
▶ 인공지능 산업에 변화를 이끌어내기 위해서는 오토라벨링을 넘어선 더 고도화된 기능이 필요하다고 본다. 즉 오픈소소 데이터셋(Open-Source Dataset)이 아닌 커스텀 데이터셋(Custom Dataset) 구축이 필요한데, 이를 위해 이른바 '인공지능 시대 인형 눈알 붙이기'라는 수작업이 불필요한 '커스텀 오토라벨링' 기술을 개발했다고 들었다.
라벨링 자동화는 말 그대로, 사람이 수작업으로 정답을 라벨링하는 과정을 AI가 자동으로 수행해주는 기술이다. 슈퍼브에이아이에서는 콜드 스타트(cold start) 상태에서 초기 학습 데이터셋을 효율적으로 구축할 수 있도록 돕기 위한 오토라벨링 및 인터랙티브 AI 기술과, 초기 데이터가 어느 정도 확보된 이후부터는 자신만의 라벨링 AI를 만들어 사용할 수 있도록 하는 커스텀 오토라벨(Custom Auto-Label) 기술을 제공하고 있다.
사람, 동물, 탈 것(자동차, 비행기 등), 실내외 소품 등 약 100여 종류의 보편적인 오브젝트들을 자동으로 라벨링 해주는 오토라벨링 기능을 사용하면, 클릭 한 번으로 초기 학습 데이터셋을 손쉽게 구축할 수 있다. 오토라벨링에서 지원하지 않는 특수한 오브젝트들은 사람이 라벨링해야 하지만, 인터랙티브 AI 기능(연말 출시 예정)을 통해 5-6 번 정도의 클릭만으로 복잡한 오브젝트의 외곽선을 정확하게 따낼 수 있다.
수백장 정도의 초기 데이터셋이 만들어지면, 그 이후부터는 커스텀 오토라벨 기능을 통해 자신만의 라벨링 AI를 원하는 만큼 생성할 수 있다. 사용자는 학습할 데이터셋을 선택하고 AI의 이름을 지어준 다음, 학습 데이터의 양에 따라 30분에서 3시간 가량 기다리기만 하면 된다.
AI 개발에 필요한 수많은 결정 요소(네트워크 구조, 최적화 알고리즘, 데이터 증강 알고리즘, 하이퍼 파라미터 등 각종 매개 변수값 최적화 등) 중 어느 하나도 사용자에게 묻지 않으며, 머신러닝이나 딥러닝에 대한 전문적인 지식 없이도 누구나 데이터셋만 있으면 해당 데이터셋으로 달성할 수 있는 최고 수준의 성능을 가진 라벨링 AI를 손쉽게 생성할 수 있다. 바운딩박스(bounding-box), 외곽선(polygon), 키포인트(keypoint), 이미지 분류(image classification) 등 다양한 태스크를 지원하고, 자신이 생성한 여러 라벨링 AI들을 원하는대로 조합해서 사용할 수도 있다.
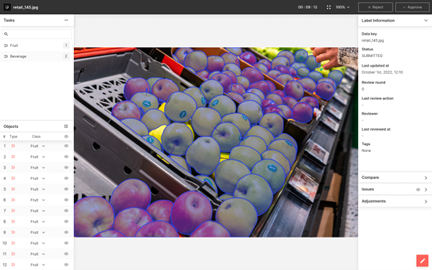
▶ 김계현 CRO는 평소 "모든 AI 는 완벽하지 않다. AI 도 오류를 낼 수 있다"면서 오토라벨링 결과물 중 오류 발생 가능성이 높은 데이터를 자동으로 검출하는 기술을 개발했다고 들었다. 인공지능 자체가 완벽한 것이 아니라, 완벽한 결과물을 위해 인공지능을 적절히 활용하는 것이 중요하다고 본다. 최소한의 검수 비용으로 데이터 라벨링 품질을 관리할 수 있는 비결은?
그렇다. 모든 AI는 오류를 낼 수 있으며, 이는 라벨링 AI도 마찬가지이기 때문에, 라벨링 결과를 사람이 검수하는 것은 데이터 라벨링 품질 보장을 위해 필수적이다. 이때 모든 데이터를 사람이 전수 검사하는 대신, 오류 발생 가능성이 높은 데이터만 자동으로 찾아내 사람에게 넘김으로써, 검수에 필요한 시간과 인력을 최소화하는 것이 바로 검수 자동화 기술이다.
슈퍼브에이아이에서는 베이지안 불확실성 추정(Bayesian uncertainty estimation) 기술을 통해 개별 예측에 대한 오류 발생 가능성을 계산한다. 상세한 내용은 기술 백서에 정리되어 있으며, 슈퍼브에이아이 홈페이지 내에서 다운로드 받을 수 있다
이 기술은 라벨링 AI의 성능이 고도화될 수록 더욱 큰 효과를 발휘하는데, 예를 들어 라벨링 AI의 정확도가 99.9%이고, 오류 1 개의 유무를 확인하는 데 1 초, 발견한 오류를 수정하는 데 5 초가 걸린다고 하자. 전수 검사를 하는 경우 1만 개 데이터의 오류 유무를 확인하는 데에만 1만 초가 소요되지만, 검수 자동화 기술을 통해 1만 개의 데이터 중에서 AI가 잘못 라벨링한 10개(= 0.1%)의 데이터를 완벽하게 골라낼 수 있다면, 검수 시간은 60 초로 줄어든다(오류 유무 확인 10 초+오류 10 개 수정 시간 50 초).
만약 검수 자동화 기술이 다소 부정확하여 100 개를 골랐다고 하더라도( precision 10%), 검수 시간은 150 초로 여전히 매우 효율적이다.
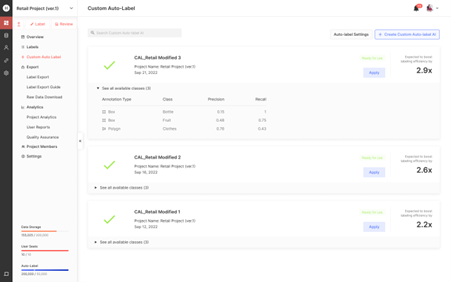
▶ AWS와의 협업(Well-Architected Deep Dive)을 통해서 슈퍼브에이아이 스위트(Suite)의 클라우드 네이티브한 B2B SaaS 플랫폼을 완성시켜 나가는 것으로 알고 있다. 스위트의 글로벌 확산을 위해서도 아주 좋은 접근인 것으로 생각된다. 향후 대형 클라우드사들과의 협업 가능성은?
현재까지는 AWS 이외에 직접적으로 협업하고 있는 클라우드사는 없지만, AWS 이외에도 여러 클라우드 서비스를 사용하고 있다. 비정형 데이터를 효율적으로 관리하고 검색하는 기능은 Elastic Cloud와 Confluent Cloud를 기반으로 개발하였고, GCP나 Azure같은 타사 클라우드에 적재된 데이터를 스위트에 연동하는 기능을 지원하기도 한다. 향후에 각 기능을 고도화하기 위해 해당 클라우드사들과 협업할 가능성도 물론 있을 것이다.
클라우드 이야기가 나온 김에 첨언하면, 데이터 보안 등의 이유로 클라우드 서비스를 사용하지 못하는 대형 고객사들을 위해, Replicated사와 협업하여 온프레미스(On-premise, 기업의 사설 인프라 안에서 구동 가능한 서비스) 버전도 개발하고 있다.
▶ 진정한 데이터 중심 인공지능(Data Centric AI)을 위해서는 대규모 데이터셋 구축과 고품질 데이터셋 구축을 기반으로 가치있는 데이터셋 구축, 즉 유사도 검색과 엣지 데이터 디텍션 등을 통한 데이터 큐레이션 자동화가 이루어 져야 한다고 전문가들은 얘기 한다.
데이터 중심 인공지능(Data-centric AI)이란, 주어진 학습 데이터에 대해 AI의 네트워크 구조와 학습 알고리즘을 엔지니어링하는 기존의 모델 중심 연구 방법론(Model-centric AI)과 대치되는 새로운 연구 방법론이다. 네트워크 구조와 학습 알고리즘은 그대로 두고, 학습 데이터셋의 가치와 품질을 개선하여(예: AI 성능 향상에 도움이 되는 유형의 데이터를 찾아내 추가하거나, 과도하게 많아 불균형을 일으키는 특정 유형의 데이터를 제거하거나, 잘못 라벨링된 데이터를 고치는 등) AI의 성능을 높이고자 하는 접근 방법이다.
보다 구체적으로, 앞에서 소개한 [원시 데이터(raw data) 수집 - 데이터 분석 및 큐레이션(curation) - 라벨링 - 검수 - AI 학습/테스트/배포 - 성능 분석 및 진단] 이라는 MLOps 사이클에서, '성능 분석 및 진단'을 네트워크 구조와 학습 알고리즘 중심으로 수행하는 경우와(예: A 알고리즘을 B로 바꾸거나, A 모듈을 B 모듈로 바꾸어 성능 비교), 데이터 중심으로 수행하는 경우로(예: A라는 데이터를 학습 데이터셋에 포함하여 학습했을 때와 제외하고 학습했을 때의 성능 비교) 예를 들 수 있겠다.
모델 중심 인공지능 개발은 숙련된 머신러닝 엔지니어가 필요하며, 개개인의 경험치와 문제 해결 능력에 따라 성과가 크게 좌우된다. ML 기술이 없거나, ML 전문 인력들의 구인/구직이 드문 분야(예: AI 기술을 기존 비즈니스에 접목하고자 하는 수많은 전통적인 분야들, 농/축산업, 패션, 제조업 등등)의 기업/조직/개인은 시도하기 어려운 방법이다. 반면 데이터 중심 인공지능 개발의 경우, 적절한 분석 알고리즘만 있다면, 진단 결과(예: A라는 유형의 데이터에서 오류가 많이 발생함)에 맞는 데이터를 확보하는 것만으로 전문가의 엔지니어링 없이도 AI의 성능을 높일 수 있다.
슈퍼브에이아이에서는 스위트의 모든 사용자들이 데이터 중심 인공지능을 통해 자신들의 AI 성능을 계속해서 높일 수 있도록, 성능 분석 및 진단 자동화 기술(내년 상반기 출시 예정)과 데이터 분석 및 큐레이션 자동화 기술을 개발, 제공하고 있다.
진단 자동화 기술은 베이지안 딥 앙상블 모델(Bayesian deep ensembles)을 통해 사용자의 AI를 시뮬레이션하고 데이터 기반의 진단 결과를 제공한다. 이는 사용된 학습 데이터가 동일하다면, 임의의 모델(proxy model)을 학습시켜 분석하더라도, 실제로 분석하고자 하는 모델(target model, 여기서는 사용자가 실제로 운용 중인 AI가 해당)과 유사한 분석 결과를 얻을 수 있다는 최근의 연구를 토대로 하고 있다.
데이터 분석 및 큐레이션 자동화 기술은 크게 3가지 기술로 구성되는데, 학습 데이터에 남아있는 라벨링 오류를 찾아내는 기술(mislabel detection), 기존에 수집된 대규모 데이터셋 안에서 진단 결과와 비슷한 데이터들을 찾아내거나(semantic search), 희소한 유형의 데이터를 선택적으로 골라내는 기술(edge case detection / 예: 눈오는 날 밤 어두운 옷을 입은 사람이 횡단 보도를 건너는 이미지)이다.
각각 데이터 단위의 영향력 추정(data influence estimation), 자가표현학습(self-supervised representation learning)과 ANN(approximate nearest neighbor), 코어셋 선택(core-set selection)에 관한 최근의 연구들을 토대로 개발되었으며, 현재 일부 사용자들을 대상으로 클로즈 베타 서비스 중이다.
▶ 슈퍼브에이아이 김현수 대표는 AI 업계 고질적인 난제인 데이터 문제를 해결하고 AI 개발 장벽을 낮춰 누구나 쉽게 AI 개발을 할 수 있도록 돕고 싶다고 대외적으로 여러 번 밝혔다. 김계현 CRO도 스위트의 진정한 강점은 유연한 플랫폼이라고, '데이터계의 깃허브'를 표방하는 스위트는 대부분의 개발자 도구 호환을 지원한다고 말한다. 그렇다면 슈퍼브에이아이의 스위트는 ML 기술이 있는 회사에도, 없는 회사에도 나아가 데이터 구축팀 뿐 아니라 ML엔지니어들 모두에게 가치를 줄 수 있는 제품이 될 수 있을까?
물론이다. 우선, 스위트의 모든 자동화 기능들은 기본적으로 ML 기술이 없는 기업/조직/개인이 손쉽게 사용할 수 있도록 기반 기술부터 UI/UX까지 세심하게 설계되어 있으며, 이를 위해 제품 기획 단계에서부터 프로덕트 오너와 디자인팀을 중심으로 머신러닝팀과 개발팀까지 모두 머리를 맞대고 긴밀하게 협업한다.
사용자는 개발자 도구(SDK)를 통해 스위트에 구축된 데이터를 자신들의 AI 학습/테스트/배포 환경에 간편하게 연동할 수 있으며, 모델 다운로드 기능(일부 고객 대상으로 서비스 중)이나 API로 원격 실행하는 기능(내년 중 출시 예정)을 이용하면 AI를 직접 학습/테스트/배포할 필요도 없이, 스위트에서 커스텀 오토라벨 기능으로 생성한 라벨링 AI들을 자신들의 비즈니스에 즉시 활용할 수 있다.
ML 기술이 있는 회사는 자신들의 MLOps 프로세스에 스위트의 기능 중 일부만을 유연하게 연동할 수 있다. 예를 들어 개발자 도구의 라벨 업로드 기능을 통해, 커스텀 오토라벨 대신 자신들의 AI를 사용하여 라벨링 자동화 프로세스를 구성할 수 있다.
또한 스위트의 [데이터 분석 및 큐레이션 기술]과 [AI 성능 분석 및 진단 기술]은, 이미 출시한 AI의 오류 원인 분석이나 성능 이슈 대응과 같은 유지보수 업무의 대부분을 자동화 해준다. 즉 회사의 소중한 머신러닝 엔지니어들을 이미 출시한 서비스의 잦은 유지 보수에 소모시키는 대신, 신규 서비스를 위한 AI 연구와 같이 더 중요한 업무에 계속해서 투입할 수 있도록 한다. 이는 머신러닝 엔지니어 개인의 커리어 관리에도, 해당 인력 리텐션에도 도움이 될 것이다.
여기까지 인터뷰를 마친 후 김계현CRO는 아래 얘기를 덧붙였다. 그에게서 현업의 개발자를 도와주고자 하는 엔지니어로서의 진정성이 느껴졌다.
"현업에 계신 많은 분들이 양질의 데이터를 확보하기 위해 다방면으로 애쓰시고, 한편으로는 주어진 데이터가 충분하지 않은 상황 속에서도 최대한의 성능을 끌어내기 위해 고군분투하시는 것, 그러한 과정, 어려움, 애로 잘 알고 있다. 서로의 고민과 노하우를 공유하는 자리가 있다면, 효율적인 데이터 수집을 위해 그동안 해왔던 경험들을 현업에 계신 분들과 공유하고 싶다. 꼭 도움이 돼드리고 싶다."
슈퍼브에이아이 김계현 CRO는?
김계현 CRO는 비전 인공지능(AI) 분야 전문가다. 마이크로소프트, 인텔, 삼성, 스트라드비전 등에서 산학계의 이목을 이끄는 다양한 연구를 진행해 왔고, 컴퓨터 비전 분야에서 출원한 특허만 해도 100개가 넘는다. 김계현 CRO는 슈퍼브에이아이 스위트의 오토라벨링 등 핵심 AI 기술을 고도화하는 역할을 맡고 있다. 비전, 딥러닝, 자율주행, 영상 인식 알고리즘 관련 특허 76종을 보유하고 있으며 그가 개발한 슈퍼브에이아이의 오토라벨링 기술 중 10건이 미국 특허 등록이 완료되었다.
류지영 전자신문인터넷 기자 (thankyou@etnews.com)



























