







AI 에이전트의 실수를 가장 잘 잡아내는 건 GPT 같은 거대 모델이 아니었다. 영국 리버풀대학교(University of Liverpool)와 프랑스 그르노블알프대학교(Universit Grenoble Alpes) 연구진이 2026년 5월 발표한 논문 '프리픽스가드(PrefixGuard)'에 따르면, 작고 가벼운 학습 모니터가 거대 언어 모델(LLM) 판사보다 최대 두 배 가까이 정확하게 에이전트의 실패를 예측했다. AI 에이전트 실패 예측은 LLM 에이전트가 작업 도중 잘못된 방향으로 가는 순간을 실시간으로 잡아내는 기술을 말하며, 단 한 번의 잘못된 행동이 돌이킬 수 없는 피해를 만들 수 있는 자동화 소프트웨어 개발, 사이버 보안, 자산 관리 같은 분야에서 점점 더 절실해지는 과제다.
거대 모델 GPT는 약했고, 작은 학습 모니터가 0.900 정확도를 기록했다
리버풀대 연구진이 발표한 '프리픽스가드(PrefixGuard)' 보고서는 LLM 에이전트의 실패를 실시간으로 감지하는 데 있어 거대 언어 모델을 판사로 쓰는 방식이 가장 약했다는 결과를 보여줬다. AI 에이전트가 웹브라우저를 조작하거나 명령어를 입력하거나 대화형 도구를 호출하는 등 긴 작업을 수행할 때, 최종 결과 검증은 너무 늦게 도착해 개입할 시점을 놓치는 경우가 많다. 연구진은 이 문제를 해결하기 위해 작업이 끝나기 전 매 단계마다 실패 위험도를 점수로 매기는 작은 감시 모델을 학습시켰다.
결과적으로 가장 강력한 프리픽스가드 모니터는 웹아레나(WebArena), 타우2벤치(τ2-Bench), 스킬스벤치(SkillsBench), 터미널벤치(TerminalBench) 네 가지 벤치마크에서 각각 0.900, 0.710, 0.533, 0.557의 AUPRC(정확도와 재현율을 종합한 지표)를 기록했다. 같은 환경에서 오픈AI(OpenAI)의 GPT-5.4-mini와 딥시크(DeepSeek)의 V4-프로(V4-Pro)를 판사로 쓴 방식은 각각 0.407과 0.450이 최고치였고, 코딩과 명령어 작업에서는 0.10대로 떨어졌다. 작고 가벼운 모델이 거대 모델보다 두 배 가까이 잘 잡아낸 것이다.
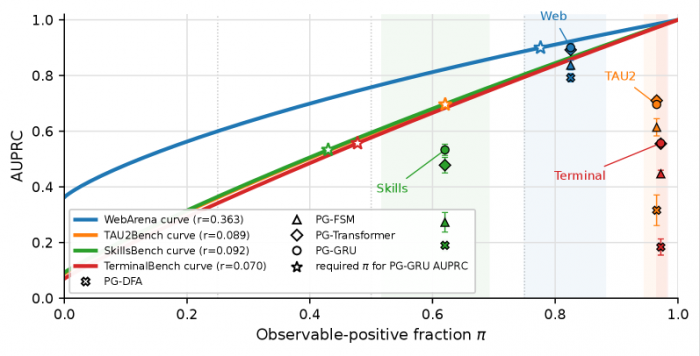
그림1. 벤치마크별 PrefixGuard 백엔드 AUPRC와 관측 가능 실패 비율(π) 비교
평균 0.137 AUPRC 향상, 표준화된 단계 정보가 핵심 비결
프리픽스가드가 거둔 성능 향상의 핵심은 '스텝뷰(StepView)'라는 단계 표준화 기술에 있다. 스텝뷰란 서로 다른 형식의 에이전트 실행 기록을 미리 정해진 일곱 가지 항목(메타데이터, 관찰값, 행동, 도구, 인자, 결과, 상태)으로 통일시켜주는 변환기다. 예를 들어 브라우저 에이전트의 단계 기록은 CSS 선택자 같은 코드 형태로 들어오고, 대화형 에이전트는 JSON 도구 호출이 대화 안에 박혀 있는 식으로 모양이 제각각인데, 스텝뷰가 이를 동일한 틀로 맞춰준다.
연구진은 GPT-5.4-나노(Nano)를 한 번만 사용해 각 데이터셋에서 약 12개 샘플로 변환 규칙을 자동 생성한 뒤, 실제 운영 단계에서는 LLM 호출 없이 고정된 코드로만 처리해 비용을 거의 들이지 않았다. 이 방식을 적용했을 때 단순히 원본 텍스트를 그대로 넣은 통제 모델 대비 평균 0.137 AUPRC가 올랐다. 이 차이가 작아 보일 수 있지만, 매일 수만 건의 AI 에이전트 작업이 누적되는 실제 운영 환경에서는 수천 건의 잘못된 행동을 미리 차단할 수 있는 수준이다. 특히 코딩 작업(스킬스벤치)에서는 0.218, 명령어 작업(터미널벤치)에서는 0.187의 향상이 있었다.
학습된 감시 모델이 GPT보다 강한 이유, 비용과 시점의 차이
거대 모델 GPT가 작은 학습 모델에 진 까닭은 두 가지다. 첫째는 비용이다. LLM을 판사로 써서 매 단계마다 위험도를 평가하려면 단계마다 거대 모델을 호출해야 하는데, 36단계 평균 길이의 작업 하나에 수십 번씩 GPT API를 호출하는 것은 실시간 감시에 부적합할 만큼 느리고 비싸다. 둘째는 정확도다. LLM 판사는 한 번도 학습되지 않은 상태에서 즉석으로 판단해야 하지만, 프리픽스가드는 실제로 실패한 수천 건의 작업 기록에서 어떤 패턴이 실패로 이어지는지를 직접 학습한다.
연구진은 GRU(순환 신경망), 트랜스포머(Transformer), 소프트-FSM(부드러운 유한 상태 기계) 세 가지 백엔드를 비교했는데, 가장 단순한 GRU가 대부분의 벤치마크에서 최고 성능을 냈다. 작업 흐름의 핵심 패턴을 짧은 기억 구조로 추적하는 것이 LLM의 거대한 추론 능력보다 이 문제에는 더 적합했다. 또한 학습된 기호를 결정론적 유한 오토마타(DFA)로 변환하면 웹아레나에서는 29개 상태, 타우2벤치에서는 20개 상태로 압축돼 사람이 직접 검토할 수 있는 형태로도 만들 수 있었다.
정확도 0.9에도 못 막은 실패, 운영 활용성은 또 다른 문제
이 논문에서 가장 의외인 발견은 마지막에 있다. 가장 높은 점수를 받은 웹아레나(0.900 AUPRC)가 실제 알람 시스템으로는 가장 약했다. 연구진이 거짓 경보율을 10% 이하로 묶고 실제로 실패한 작업을 미리 잡아낸 비율을 측정했더니, 웹아레나는 28.7%만 잡아냈고 그것도 작업 종료 직전에야 경보가 울렸다.
반면 0.710 AUPRC로 점수는 더 낮았던 타우2벤치는 97.9%의 실패 작업을 미리 잡아냈고, 실제 개입이 가능한 이른 시점에 경보를 울렸다. 보고서는 이 현상을 '순위 매기기'와 '경보 작동'이 다른 능력이라고 설명한다. 점수가 높다는 건 위험한 작업을 위험하다고 잘 정렬한다는 뜻이고, 경보가 잘 작동한다는 건 거짓 경보를 일으키지 않으면서도 충분히 이른 시점에 신호를 보낸다는 뜻이다. 둘은 별개의 문제라는 게 이 논문이 드러낸 진짜 통찰이다.
FAQ ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. AI 에이전트 실패 예측이란 무엇인가요?
AI 에이전트가 여러 단계로 작업을 수행하는 도중에 잘못된 방향으로 가고 있는지를 실시간으로 감지하는 기술을 말합니다. 작업이 완전히 끝난 뒤에 실패를 확인하면 이미 돌이킬 수 없는 피해가 발생할 수 있기 때문에, 작업 중간 단계마다 위험도를 점수로 매겨 미리 경고를 보내는 방식입니다.
Q2. 왜 GPT 같은 큰 모델보다 작은 학습 모델이 더 잘 잡아내나요?
큰 모델은 매번 호출할 때마다 비용과 시간이 많이 들어 실시간 감시에 부적합하고, 한 번도 학습되지 않은 상태에서 즉석으로 판단해야 합니다. 반면 작은 학습 모델은 실제로 실패한 작업 기록을 미리 학습해 어떤 패턴이 실패로 이어지는지를 정확히 알고 있어, 빠르고 정확하게 위험을 잡아낼 수 있습니다.
Q3. 정확도가 높으면 실제로도 잘 쓸 수 있는 건가요?
꼭 그렇지는 않습니다. 이번 논문이 보여준 가장 중요한 발견 중 하나는 정확도(AUPRC)가 높아도 실제 운영 환경에서는 거짓 경보가 많거나 너무 늦게 경보가 울려서 쓸모없는 경우가 있다는 점입니다. 실전에서는 거짓 경보를 줄이면서 충분히 이른 시점에 경보를 보내는 능력이 따로 평가되어야 합니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: PrefixGuard: From Large Language Model Agent Traces to Online Failure-Warning Monitors
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)



































