주경돈 인공지능대학원 교수팀
그림에 원근감 부여하는 '소실점' 활용
자율주행차와 로봇 시력 업

자율주행차 눈 역할을 하는 카메라의 주변 인식 정확도를 높일 수 있는 인공지능(AI) 기술이 개발됐다. 평면 그림에 원근감을 부여하는 '소실점'을 응용한 기술이다.
주경돈 울산과학기술원(UNIST)은 인공지능대학원 교수팀은 카메라에 입력된 정보의 원근 왜곡 문제를 보정·개선할 수 있는 AI 모델 'VPOcc'를 개발했다고 15일 밝혔다.
자율주행차나 로봇은 카메라나 라이다(LiDAR) 센서로 주변을 인식한다. 카메라는 색·형태 등 풍부한 정보를 인식하지만 3차원 공간을 2차원 이미지로 인식해 거리에 따른 크기 왜곡이 많다. 같은 크기여도 가까운 물체는 더 크게, 먼 물체는 더 작게 인식한다.
주 교수팀은 AI가 소실점을 기준으로 정보를 재구성하도록 설계해 이 문제를 해결했다.
소실점은 르네상스 시대 화가들이 정립해 내려온 그림 속 원근감 부여 기법이다. 차선이나 철로 같이 실제로는 평행한 선들이 멀리서는 맞닿는 것처럼 보이는 지점을 말한다. 평면 화폭 위 소실점은 깊이감을 느끼게 한다.
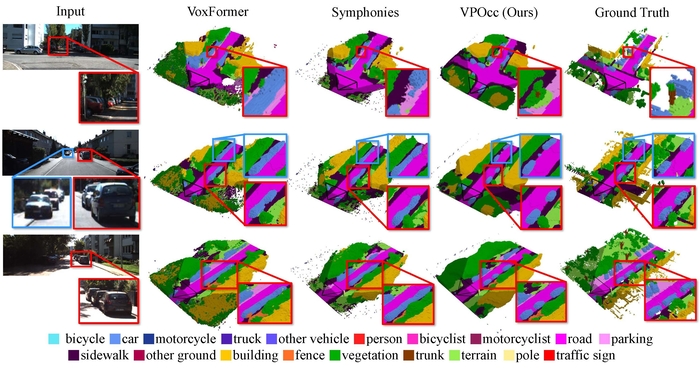
'VPOcc'는 이 소실점 활용해 원근을 인식하는 인공신경망 모델이다. 소실점을 기준으로 삼아 카메라 영상 속에서 깊이와 거리를 더 정확하게 인식하고 복원한다.
'VPOcc'는 세 가지 모듈로 구성됐다. 소실점을 기준으로 영상을 보정해 원근 왜곡을 줄이는 모듈(VPZoomer), 멀고 가까운 영역에서 균형 잡힌 정보를 추출하는 모듈(VPCA), 원본과 보정 영상을 합쳐 서로의 약점을 보완하는 모듈(SVF)이다.
'VPOcc' 테스트 결과, 기존 모델 대비 공간 이해 능력(mIoU)과 복원 능력(IoU)이 모두 우수했다. 자율주행에 중요한 도로 환경에서 멀리 있는 객체를 보다 선명하게 예측하고, 겹쳐 있는 객체도 더 정확히 구분했다.
연구개발을 주도한 김준수 UNIST 연구원은 “사람이 공간을 인식하는 방식을 AI에 접목하면 3차원 공간을 더욱 효과적으로 이해할 것이라는 생각에 연구를 시작했다”며 “라이더 센서보다 가격 경쟁력과 경량화 측면에서 유리한 카메라 센서 활용성을 극대화하고, 로봇이나 자율주행 시스템 뿐만 아니라 증강현실(AR) 지도 제작 등 다양한 분야에 응용할 수 있 수 있을 것”이라고 말했다.
울산=임동식기자 dslim@etnews.com