







위성이 찍은 사진을 더 이상 전부 지구로 내려보내지 않는다. 대신 사진을 본 위성이 "이건 해안가 항구이고, 다리가 작은 섬으로 이어진다"라고 글로 설명해서 보낸다. 2026년 4월 16일, 미국 항공우주국(NASA) 제트추진연구소(JPL)가 개발하고 위성 기업 로프트 오비탈(Loft Orbital)의 위성에 탑재한 나비 오비탈(NAVI-Orbital)이 지구 궤도를 도는 위성 안에서 시각 언어 모델(Vision-Language Model)을 직접 돌려 사진을 이해하고 설명하는 데, 연구팀이 아는 한 처음으로 성공했다. 시각 언어 모델이란 사진과 글을 동시에 이해하는 AI로, 사진을 보고 사람처럼 말로 풀어내는 챗봇이라고 생각하면 된다. 우리가 매일 쓰는 인공위성 지도와 기상 정보가 어떻게 만들어지는지, 그리고 그 방식이 지금 어떻게 뒤집히고 있는지를 보여주는 사건이다.
위성이 사진 대신 글을 내려보내는 시대의 개막
나비 오비탈은 위성이 찍은 사진을 지구로 보내는 대신, 사진을 본 AI가 작성한 글 설명을 내려보내는 방식을 우주에서 처음으로 실증한 시스템이다. NASA JPL과 로프트 오비탈이 함께 만들어 저궤도(LEO) 위성 얌나인(YAM-9)에 탑재했고, 구글(Google)의 AI 모델 젬마3(Gemma 3)를 위성 안에서 직접 작동시켰다. 핵심은 위성이 사진을 단순히 찍어 두는 게 아니라, 그 자리에서 "무엇이 찍혔는지"를 스스로 판단하고 평범한 영어 문장으로 설명한다는 점이다.
지금까지 인공위성은 일단 사진을 잔뜩 찍은 뒤 지구로 모두 내려보내고, 지상의 사람이 그 사진을 일일이 들여다보는 방식으로 일해왔다. 문제는 위성이 사진을 찍는 속도가 지구로 데이터를 보내는 속도를 한참 앞질렀다는 데 있다. 통신할 수 있는 시간은 위성이 지상국 위를 지나가는 짧은 순간뿐인데, 찍어둔 사진은 산더미처럼 쌓인다. 나비 오비탈은 이 병목을 정반대 방향에서 푼다. 사진을 먼저 다 보내는 게 아니라, AI가 요약한 글을 먼저 보내고 사람이 "그 사진 보여줘"라고 요청한 중요한 장면만 골라서 받는 것이다.
약 1만 분의 1로 줄어든 데이터, 픽셀이 아니라 의미를 압축하다
나비 오비탈의 가장 강력한 무기는 데이터 크기를 약 1만 배(자릿수로 네 자릿수) 줄이는 의미 압축(Semantic Compression) 기술이다. 의미 압축이란 사진의 픽셀을 줄이는 게 아니라, 사진이 담은 내용을 글로 바꿔 핵심 의미만 남기는 방식을 말한다. 논문에 따르면 위성이 찍은 원본 사진 한 장은 약 9~14메가바이트(MB)인데, AI가 그 사진을 설명한 글은 700~1060바이트에 불과하다. 사진 한 장과 그 설명 글의 용량 차이가 약 1만 배, 자릿수로 따지면 네 자릿수나 차이가 난다.
이 숫자가 작아 보일 수 있지만 실제 운영에서는 완전히 다른 결과를 만든다. 사진 한 장 보낼 시간에 글 설명은 수천 장을 보낼 수 있다는 뜻이기 때문이다. 위성은 지나가는 모든 장면에 대해 "여기는 농경지, 저기는 야간 도시"라는 설명을 빠짐없이 지구로 내려보내고, 지상의 운영자는 그 목록을 훑어본 뒤 정말 필요한 고화질 사진만 골라 요청한다. 새 지상 장비를 깔거나 위성 저장 공간을 늘리지 않고도, 사진을 다 받아 보던 기존 방식의 한계를 그대로 우회한다.
다시 가르치지 않아도 처음 보는 장면을 알아맞히는 만능 AI
나비 오비탈은 따로 추가 학습을 시키지 않아도 처음 보는 위성 사진을 알아보는 제로샷(Zero-Shot) 능력을 갖췄다. 제로샷이란 특정 대상만 콕 집어 훈련받지 않았는데도, 인터넷으로 폭넓게 배운 일반 지식만으로 새로운 것을 알아맞히는 능력을 말한다. 연구팀이 7960장 규모의 위성 사진 데이터셋(AID)으로 시험한 결과, 나비 오비탈은 88.16%의 정확도와 0.87의 F1 점수를 기록했다. 단 한 번의 추가 훈련 없이 18종류의 지형과 시설을 구분해낸 수치다.
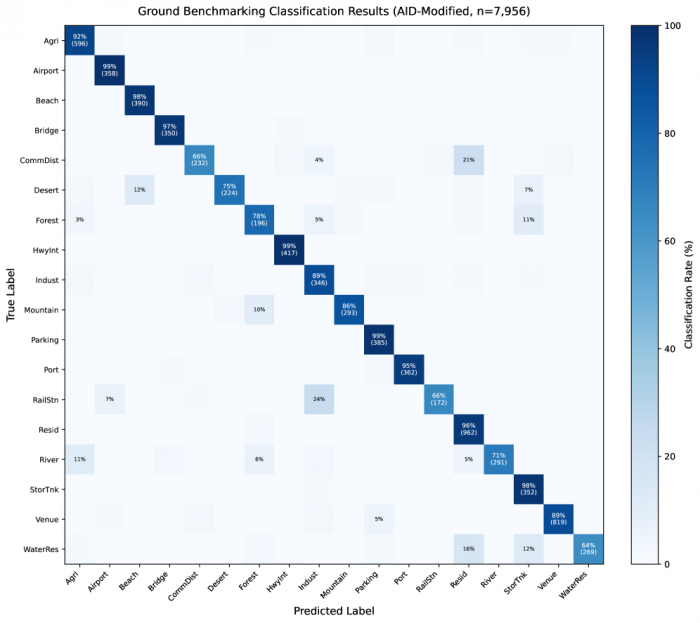
그림1. AID 데이터셋 18종 제로샷 분류 혼동 행렬 (출처: NAVI-Orbital 논문, Figure 5)
이 지점에서 기존 위성 AI와의 차이가 분명해진다. 지금까지 위성에 실리던 AI는 "배를 찾아라", "구름을 찾아라"처럼 특정 목표 하나만 찾도록 미리 훈련된 전문 검출기였다. 새로운 대상을 찾으려면 모델을 처음부터 다시 훈련하고, 검증하고, 복잡한 소프트웨어를 위성에 다시 올려야 했다. 느리고 비싸고 번거로웠다. 반면 나비 오비탈은 위성에 평범한 영어로 "이번엔 공항과 항구를 찾아줘"라고 문장만 바꿔 보내면 임무가 바뀐다. 모델을 다시 훈련할 필요 없이, 명령 한 줄을 고쳐 쓰는 것만으로 위성에게 새 일을 시킬 수 있다. 위성과 사람이 마치 대화하듯 일하는 셈이다.
영하의 우주에서 20초마다 사진을 읽어낸 손바닥 위 컴퓨터
나비 오비탈은 대형 서버가 아니라 위성에 들어가는 작은 저전력 컴퓨터 위에서, 외부 인터넷 연결 없이 모든 판단을 스스로 해냈다. 위성은 전기도 부족하고 열을 식히기도 어려운 가혹한 환경이다. 그런 조건에서 수십억 개의 변수를 가진 AI 모델을 돌리는 건 쉽지 않다. 연구팀은 모델의 정밀도를 낮춰 메모리를 아끼는 양자화(Quantization)라는 기술로 무거운 AI를 손바닥만 한 컴퓨터에 욱여넣었다. 양자화란 AI가 쓰는 숫자의 자릿수를 줄여 용량과 전력을 아끼되 성능은 최대한 지키는 방법을 말한다.
그 결과 위성은 2026년 4월, 프랑스 툴루즈와 아르헨티나 해안을 직접 촬영해 그 자리에서 분석했다. 한 장면을 찍고 다음 장면으로 넘어가는 20초 사이에 사진을 읽고 설명까지 끝냈다. 보정도 거치지 않은 날것의 사진을 받고도 아르헨티나 장면을 "모래 해변이 펼쳐진 해안 지역"이라고 정확히 설명했다. 처음 보는 실제 위성 사진을, 지상의 도움 없이, 우주에서 혼자 해석한 것이다. 다만 연구팀은 이 AI가 가끔 없는 사실을 지어내는 환각(Hallucination) 현상을 완전히 막지는 못한다고 분명히 밝혔다. 시험 중에도 허용되지 않은 "골프장" 같은 엉뚱한 답을 만들어낸 사례가 있었고, 재시도 장치로 대부분 걸러냈지만 가능성을 0으로 만들지는 못했다.
생각하는 위성 시대, 무엇을 더 지켜봐야 하나
나비 오비탈은 위성을 "찍는 기계"에서 "보고 판단하는 기계"로 바꾸는 첫걸음일 가능성이 있다. 재난 현장을 위성이 스스로 알아보고 가장 급한 장면부터 지구로 알려주거나, 운영자가 우주의 위성과 채팅하듯 정보를 주고받는 미래가 더 가까워졌다. 명령어 전문가가 아니어도 평범한 문장으로 위성에 일을 시킬 수 있다는 점은, 위성 활용의 문턱 자체를 낮춘다.
다만 연구팀 스스로 강조했듯 이번 성과는 "가능성의 증명"이지 "완성된 시스템"은 아니다. AI가 가끔 사실을 지어내는 문제가 남아 있는 한, 위성이 내린 판단을 곧바로 다른 장비나 임무에 연결하는 일은 더 두고 볼 필요가 있다. 예를 들어 AI의 설명 하나만 믿고 위성이 자동으로 다른 행동을 하게 만드는 것은 아직 풀리지 않은 숙제다. 그럼에도 우주에서 AI가 처음으로 눈을 뜨고 자기가 본 것을 말로 옮겼다는 사실은, 앞으로의 위성이 어떤 방향으로 진화할지를 보여주는 분명한 신호다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. 나비 오비탈은 위성에 챗GPT를 넣은 건가요?
정확히는 챗GPT가 아니라 구글이 만든 AI 모델 젬마3(Gemma 3)를 위성에 직접 넣은 것입니다. 사진을 보고 글로 설명하며 사람의 질문에 답할 수 있다는 점에서 챗봇과 비슷하지만, 인터넷 연결 없이 위성 안에서 혼자 작동한다는 점이 다릅니다.
Q. 사진을 안 보내고 글만 보내면 진짜 사진은 못 보나요?
볼 수 있습니다. 위성이 먼저 모든 장면의 글 설명을 내려보내면, 지상의 운영자가 그 설명을 보고 정말 필요한 장면만 골라 고화질 원본 사진을 요청하는 방식입니다. 중요한 사진만 골라 받으니 제한된 통신 시간을 훨씬 효율적으로 쓸 수 있습니다.
Q. 이 기술이 우리 생활과 무슨 상관이 있나요?
우리가 쓰는 지도, 날씨 예보, 재난 감시는 모두 위성 사진에 기반합니다. 위성이 스스로 사진을 이해하고 중요한 정보를 빠르게 골라 보낼 수 있게 되면, 산불이나 홍수 같은 긴급 상황을 더 빨리 파악하고 대응하는 데 도움이 될 수 있습니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: NAVI-Orbital: First In-Orbit Demonstration of a Zero-Shot Vision-Language Model for Autonomous Earth Observation
해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. (☞ 기사 원문 바로가기)
AI 리포터 (Aireporter@etnews.com)



































