한국과학기술원(KAIST·총장 이광형) 연구진이 새로운 패러다임의 동영상 인식기술 개발에 성공했다.
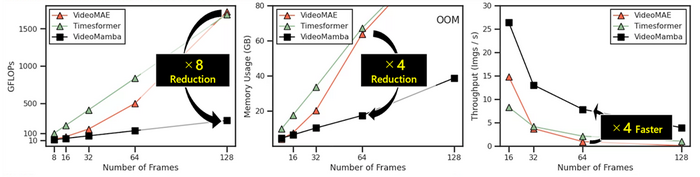
거대언어모델(LLM)의 근간이 되는 '트랜스포머'로 구축한 기존 비디오 모델보다 연산량은 8배, 메모리 사용량은 4배 낮으면서도 높은 정확도를 기록했다. 추론 속도는 기존 트랜스포머 기반 모델 대비 4배 빠른 속도를 달성했다.
KAIST는 김창익 전기 및 전자공학부 교수팀이 이와 같은 초고효율 동영상 인식 모델 '비디오맘바'를 개발했다고 23일 밝혔다.
비디오맘바는 기존 트랜스포머 기반 모델이 가진 높은 계산 복잡성을 해결하기 위한 모델이다. 트랜스포머 기반 모델은 '셀프-어텐션'이라는 메커니즘에 의존해 계산 복잡도가 제곱으로 증가하는 문제가 있다.
비디오맘바는 '선택적 상태 공간 모델(SSM:매개변수를 조정해 시퀀스 데이터 문맥을 잘 이해하는 상태 공간 모델)' 메커니즘을 활용해 효율적인 처리가 가능하다.
동영상 시공간 정보를 효과적으로 포착해 긴 동영상 데이터도 효율적으로 처리한다. 순서가 없는 공간 정보와 순차적인 시간 정보를 효과적으로 통합해 인식 성능을 높였다.

비디오맘바는 다양한 응용 분야에서 솔루션을 제공할 수 있다. 자율주행에서는 주행 영상을 분석해 도로 상황을 정확하게 파악하고, 보행자·장애물을 실시간 인식해 사고를 예방할 수 있다.
의료 분야에서는 수술 영상을 분석해 환자 상태를 실시간으로 모니터링하고 긴급 상황 발생 시 신속 대처할 수 있다. 스포츠 분야에서는 경기 중 선수 움직임·전술을 분석해 전략을 개선하고, 훈련 중 피로도나 부상 가능성을 실시간 감지해 예방할 수 있다.
김창익 교수는 “비디오맘바의 빠른 처리 속도와 낮은 메모리 사용량, 뛰어난 성능은 우리 생활에서의 다양한 동영상 활용 분야에 큰 장점을 제공할 것”이라고 밝혔다.
이번 연구에는 KAIST 전기 및 전자공학부의 박진영 석박사통합과정, 김희선 박사과정, 고강욱 박사과정이 공동 제1 저자, 김민범 박사과정이 공동 저자, 김창익 교수가 교신 저자로 참여했다. 연구 결과는 올해 9월 '유러피언 콘퍼런스 온 컴퓨터 비전(ECCV) 2024'에서 발표될 예정이다.
한편, 이번 연구는 과학기술정보통신부 재원으로 정보통신기획평가원(IITP) 지원을 받아 수행됐다.
김영준 기자 kyj85@etnews.com