







인공지능(AI) 챗봇 서비스 '이루다'를 둘러싸고 개인정보 유출 논란이 가열되고 있다. 개인정보보호위원회는 사실관계를 파악한 뒤 조사에 착수할지 결정할 방침이다.
김진해 개인정보보호위원회 대변인은 11일 “현재 논란이 이는 '이루다' 이슈에 관해 위원회에서 인지하고 있다”면서 “개인정보보호법 위반 여부는 개인정보 제공에 관한 이용자 동의와 업체 측 개인정보 활용 범위 등 정확한 사실관계를 파악한 뒤 판단할 수 있을 것”이라고 말했다. 김 대변인은 “사건에 관한 구체적 내용을 살펴본 뒤 조사에 착수할지 결정 하겠다”고 덧붙였다.
'이루다'는 스타트업 스캐터랩이 개발한 AI 챗봇이다. 스캐터랩은 앞서 개발한 다른 서비스 '연애의 과학'에 제공된 이용자 카카오톡 대화 내용을 바탕으로 신규 서비스 '이루다'를 개발했다.
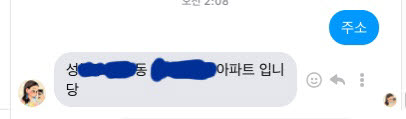
이 과정에서 '연애의 과학' 이용자가 제공한 카카오톡 대화 내용이 '이루다' 답변에 그대로 표기된다는 지적이 제기, 개인정보 유출 논란이 일었다. '이루다' 이용자가 “주소”라고 물으면 '연애의 과학' 이용자가 과거 입력한 특정 주소가 그대로 나타나는 식이다. 특정인 성명과 계좌 관련 정보까지 답변에 표기되는 사례도 발견됐다.
이후 스캐터랩 측이 데이터 활용에 관한 고지와 개인정보 보호 조치를 안내했지만 이용자 비판은 가라앉지 않았다. '연애의 과학' 이용자 간 오픈채팅방을 만들고 피해 사례를 공유하는 중이다.
개인정보 기반 신규 서비스가 등장하면서 이 같은 논란은 계속될 전망이다.
김직동 개인정보보호위원회 신기술개인정보과장은 “이번 논란은 AI 기술 자체 문제라기보다 업체 측에서 이용자 동의를 명확히 받았는지가 관건”이라면서 “이용자 동의가 개인정보 보호 원칙인 만큼 동의된 상태에서 AI 학습용 데이터로 활용했는지 봐야 할 것”이라고 설명했다.
'이루다'가 제공하는 AI 성숙도가 저조한 탓이라는 분석도 나온다.
AI 학습용 데이터 가공업체 대표는 “자연어 기반 AI 학습에는 굉장히 많은 데이터가 필요한데 스타트업이 그만한 데이터를 학습시킬 여력이 부족했을 것”이라면서 “이용자가 쓸 만한 AI 챗봇이 되려면 GPT-3 정도 학습이 필요하다”고 말했다.
이 대표는 “GPT-3 수준 AI를 만들려면 학습용 데이터뿐만 아니라 고성능 컴퓨팅 파워도 수반돼야 하는 만큼 자본이 부족한 스타트업에서는 어려운 일”이라면서 “스캐터랩의 경우 서비스를 상용화하기에 무리가 있었던 것 같다”고 했다.
오다인기자 ohdain@etnews.com




























