인공지능(AI)이 데이터를 통해 인간처럼 읽고 듣는 감각기관에 해당하는 지능을 언어지능과 청각지능이라 한다. 즉 음성(구어)이나 텍스트(문어) 등 자연어를 이해하고 요약 또는 통·번역 등을 하는 기술을 의미한다.
자연어는 사람이 일상으로 사용하는 언어 구조 체계로, 인공으로 만들어진 언어인 인공어(人工語)와 구분해 부르는 개념이다. 따라서 자연어는 단어 의미와 문장 전체 맥락, 발화 의도를 파악하기 어려운 대표적 비정형 데이터다.
이에 반해 인공어는 특수한 목적을 위해 만들어진 언어며 다른 말로 기계어라 하기도 한다. 자연적으로 생성된 자연어와 달리 한 사람이나 여러 사람 의도와 목적에 따라 만든 언어, 즉 형식언어다. 특정한 형식 문법 법칙이나 정규 표현식에 따라 생성되는 문자열 집합, 튜링머신이나 유한상태기계 등 자동기계에 의한 문자열 집합 등이 여기에 포함된다.
자연어처리(NLP)는 사람이 내뱉은 비정형적 자연어를 컴퓨터가 이해할 수 있는 정형적 언어 데이터로 바꾸는 기술이다. 컴퓨터가 문장 의도를 이해하고 말한 사람 의도를 정확히 파악할 수 있도록 해주는 과정이다.
AI 서비스에서 NLP는 중요한 부분을 차지한다. 컴퓨터가 자연어를 문법상 의미 최소 단위인 형태소로 분해(파싱)해 언어학적 구조를 패턴화, 전체 의미를 파악하도록 해준다. 하나의 품사에 여러 모호성을 해소하는 품사 태깅, 불용어 제거, 기계번역, 대화시스템에 이르기까지 모든 과업을 수행한다.
최근에는 딥러닝 기반 NLP 연구가 늘고 있다. 단어 단위가 아닌 문장 전체 맥락에서 의미를 추론할 수 있게 됐다. 딥러닝을 적용하기 위해서는 말뭉치(코퍼스, Corpus)라는 학습용 언어 데이터를 필수로 확보해야 한다.
NLP를 기반으로 한 음성인식 기술은 대용량 음성 데이터를 저장하고 실시간으로 처리 가능한 네트워크와 컴퓨팅 기술로 크게 진화하고 있다. 음성인식 기술 핵심은 상대방과 대화를 계속 이어가는 것이다.
이를 위해선 상대방이 말하는 관용적 표현을 제대로 이해하고 쉬는 구간도 인지하는 등 고도 AI 기술이 필요하다. 목소리가 주변 소음과 섞여 있을 때 목소리만 추출해 인식하는 음 분리 기술도 중요하다. 음 분리 기술이 뛰어날수록 인식률도 높다.
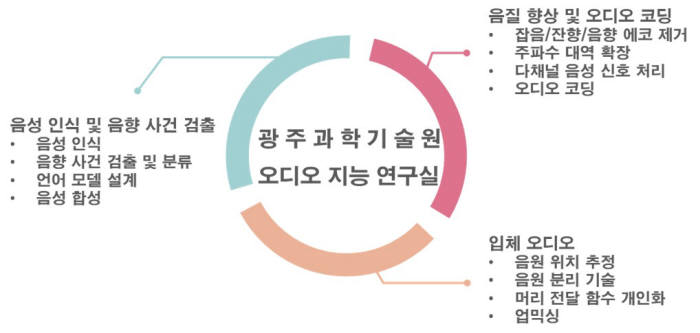
광주과학기술원(GIST·총장 문승현) 김홍국 전기전자컴퓨터공학부 교수는 '오디오 지능 연구실'에서 AI기반 언어 및 청각지능에 대해 연구하고 있다. 음성인식을 위한 전처리기술을 개발하고 있으며, 다른 사람 말소리 등 주변 환경 잡음에 영향을 받지 않는 다채널 음성인식 전처리 분야를 연구하고 있다. 뿐만 아니라 딥러닝 모델을 사용한 음성 복원 및 강화도 핵심 연구 대상이다.
김 교수가 개발하는 음성인식 시스템은 크게 음성 특징 추출, 음향 모델링, 발음사전 모델링, 언어 모델링으로 구성돼 있다. 컴퓨터로 음성을 분석하고 특징을 추출한 뒤 각 음소를 대표하는 확률 값을 심층신경망(DNN)으로 모델링한다. 발음사전 모델링에서는 언어 기본 소리를 정의하고 음향 및 언어 모델 사이 연결을 목적으로 순환신경망(RNN)을 구축한다.
통계 기반인 n-그램 언어모델링은 음성 데이터베이스로부터 가능한 단어열의 확률 값을 통계로 추정하는 방식이다. 신경망 분석을 기반으로 하는 언어모델도 연구하고 있다. 기존 통계기반 음향모델 대신 딥러닝 기법을 사용하는 end-to-end 한국어 음성인식기 연구도 진행하고 있다.
음성인식 기법은 음향사건검출 및 인식에 활용되어 AI 비서가 주변 상황을 인지할 수 있도록 진화하고 있다. 김 교수는 여러 배경 소음이 혼재하는 실제 환경에서 이상 음향을 분류해 검출했다. 딥러닝, 특히 합성곱신경망과 장단기메모리(LSTM)를 통해 폭발음, 유리깨짐음, 총소리, 비명, 아기 울음, 차량 충돌, 차량 경적, 타이어 마찰음, 사이렌음 총 9개 오디오 패턴을 모델링했다.
이 기술은 총소리나 유리창이 깨지는 등 비정상적 사운드를 감지해 사용자에게 알려주는 기능으로 보안 카메라 시장이나 국방안보 기술, 야간이나 터널 내에서 사고음 인식 등 주요한 재난안전 요소 기술이다.
또 오디오가 겹쳐 존재하는 구간에 대해 오디오 객체를 분리하고 각각 오디오 객체에 인식을 수행해 주변 잡음 환경으로부터 다수 실사 오디오를 추출하는 연구와 오디오 정보로부터 오디오가 발생한 상황에 대한 장면을 분류하는 기술도 선보였다. 이 기술은 미국 전기전자기술자협회(IEEE)가 진행하는 '음향장면 및 사건의 검출과 분류' 챌린지에 참여해 세계 유수 기관과 기술 경쟁을 벌이고 있다.

광주=김한식기자 hskim@etnews.com